Spark 计算成本优化实践
Download
聚焦模式
字号
成本优化是一个持续不断的过程。由于大数据的动态性和不断变化的性质,企业用户成本优化的活动应该持续不断的进行。本文为您介绍在数据湖计算 DLC 中,基于 Spark 计算资源,如何进行成本优化的相关实践。您可以参考我们提供的使用场景,按需使用优化。
如何选择合适的计算资源付费方式
数据湖计算 DLC 支持引擎通过按量付费与包年包月两种付费模式进行购买。
资源描述 | 按量付费计算资源 | 包年包月计算资源 | 弹性计算资源 |
费用标准 | 0.35元/CU*时 表示使用1CU资源一个小时收费0.35元。按实际使用的资源的CU量计费 | 150元/CU*月 表示1CU资源一个月的费用为150元 | 0.35元/CU*时 表示使用1CU资源一个小时收费0.35元。按实际使用的资源的CU量计费 |
付费方式 | 后付费 | 预付费 | 后付费 |
使用特点 | 1. 用户可以灵活选择资源的使用时间:当用户不使用按量资源时,可以选择将资源挂起(释放),挂起后不再继续收费。 2. 按量资源在用户拉起集群运行任务时才会分配给用户,分配成功后由当前用户独占;但受资源池影响,可能出现资源不足按量资源无法分配出来的情况。 | 1. 资源在购买后就会分配给用户独占,不会出现资源无法分配的情况。 2. 随时可用。同时支持加购弹性资源,并按量计费。 | 1. 弹性计算资源是基于购买了 Spark 包年包月集群的基础下,额外开通按量计费资源。 2. 弹性资源能够在必要的时候加快任务的运行速度,减少整个系统的负载。同时在任务较少时,弹性资源自动释放,不再收费,有效降低成本。 |
推荐场景 | 1. POC 测试阶段 2. 每个月使用时长不超过18天 | 1. 正式的生产环境 2. 适合任务量大且稳定的数据计算场景 3. 使用时间超过一个月总时间的60%,使用包年包月会更划算 | 1. 正式的生产环境 2. 购买的包年包月计算资源运行任务,任务的完成时间不符合预期 |
是否支持付费方式切换 | 是 | 否 | 否 |
场景:由于包年包月计算资源不足,导致任务完成时间不达预期
某电商平台采购了 128CU 包年包月的计算资源去保障600个分析任务可以在当日完成运行与结果返回。
随着电商大促来临,数据量激增,他们发现这段时间已无法保障任务的完成时效。通过分析,发现问题在于目前购买的资源无法满足大促期间的数据处理需求,从而导致任务排队等待,进而延误进度。面对这一状况,企业希望可以有一个既能短期保障任务按时完成,又能把成本控制在合理范围内的方案。
推荐方案:
大促期间,在128CU包年包月的基础上,额外购买128CU弹性计算资源,根据任务负载情况,当包年包月的128CU都在使用时,触发弹性资源运行,提升运行效率。大促结束后,关闭弹性功能,有效控制成本投入。
任务量少:按量计费的弹性资源自动释放,不再收费,有效降低成本。
任务量多:按量计费的弹性资源能够在必要的时候加快任务的运行速度,用多少,费用收多少。
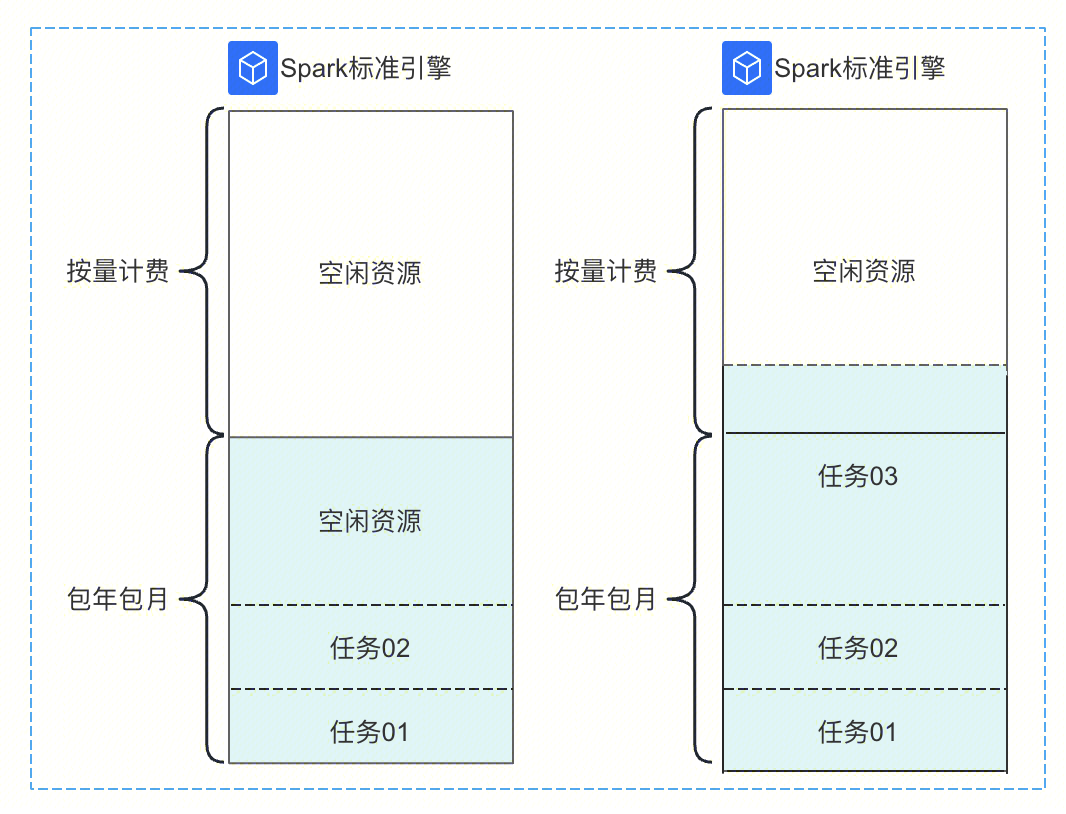
开通步骤:
1. 进入引擎列表页,确认需要配置弹性计算资源的包年包月引擎。
2. 在操作栏单击“更多”,选择规格配置。
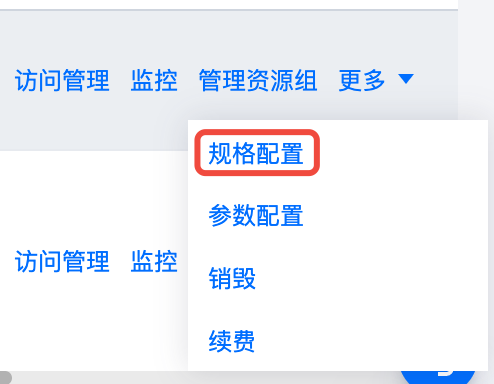
3. 打开弹性计算资源开关,并选择弹性配置规格。
注意:
弹性计算规格大小不能超过包年包月的规格。
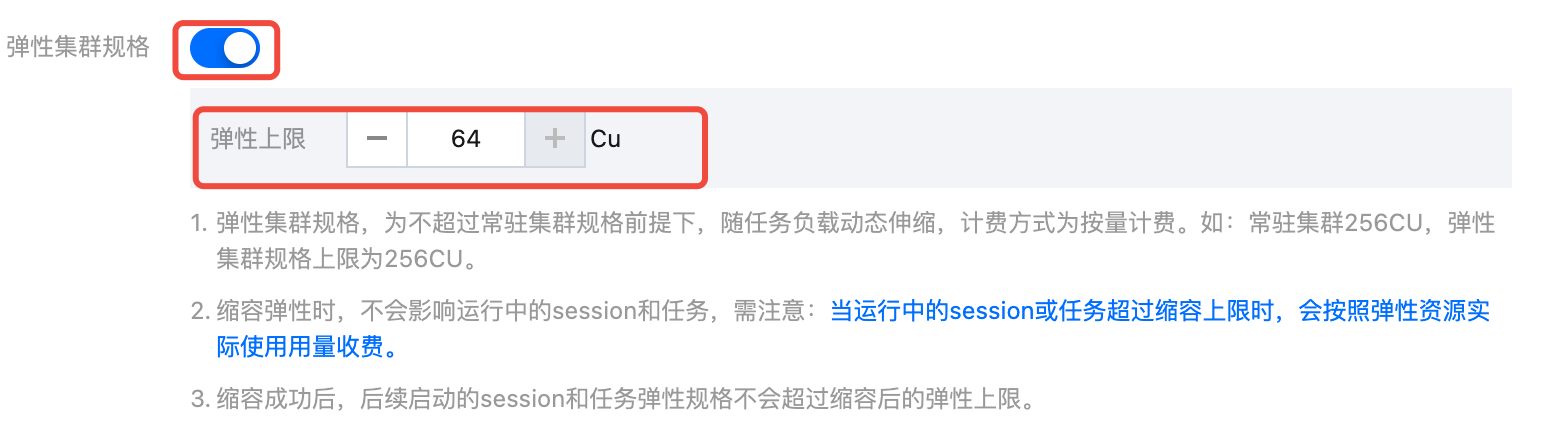
4. 大促结束后,恢复正常任务运行,可单击规格配置,关闭弹性集群功能。
如何合理规划计算资源分配
方式一:通过多个引擎进行计算资源分配
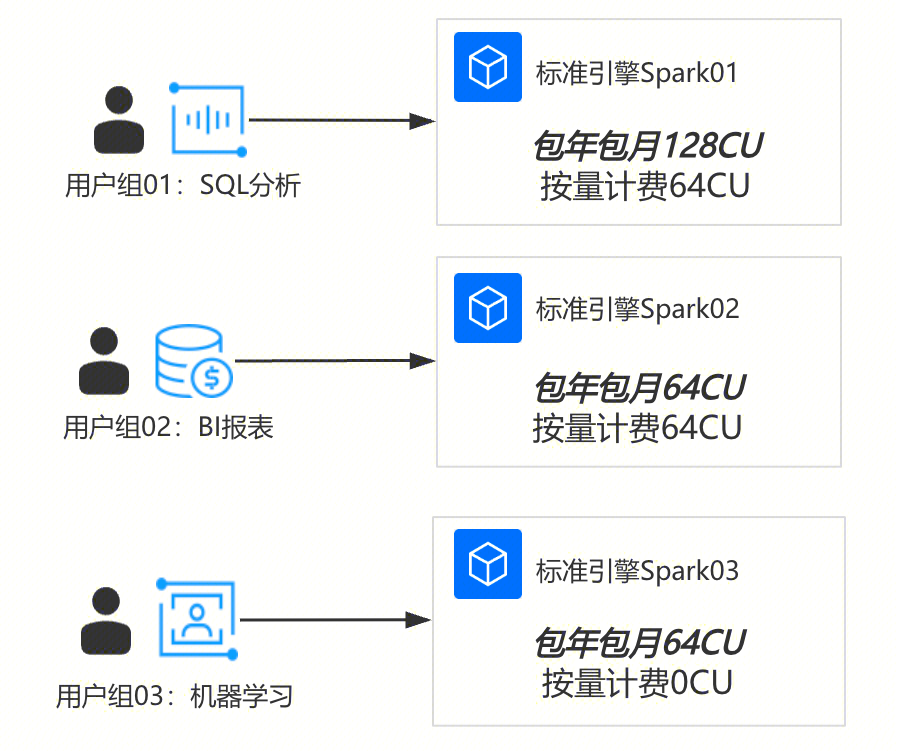
通过购买多个计算资源,分配给不同用户组或功能场景,每个计算资源独立运行任务。
优势 | 不同引擎之间资源完全隔离,由当前用户组独占。不同用户组之间的配置、管理、任务和故障都相互不影响。 |
适用场景 | 1. 多部门需要使用平台,但彼此之间没有业务重合,多为独立业务分析场景。 2. 对成本审计、安全运维有较高要求的企业。 |
局限 | 资源有可能会有空闲时间,利用无法最大化。如图用户组01主要做SQL分析,主要在早上9点到下午5点之间使用资源,其他时间资源处于空闲状态。 解决方式:调整计算资源为按量计费资源、调整资源分配方式。 |
方式二:一个引擎通过资源组进行资源分配
该模式下,所有用户组或功能场景使用同一个引擎,但每个用户使用配置不同的资源组来进行资源分配。
优势 | 能够实现计算资源利用最大化。 |
适用场景 | 1. 对成本控制有较高要求。 2. 需要配置的资源组数量不多,且多为线性启动任务,较少并发任务。 3. 各任务运行时间不会产生太多重合,且重合任务消耗计算量不超过资源总量。 |
局限 | 不同的资源组之间可能会形成资源竞争,如图三个用户均在使用的情况下,如果用户一占用了256CU资源,用户二也占用了256CU资源,此时引擎维度的所有资源均被占用,用户三会分配不到资源,导致用户三任务无法运行。 解决方式:增加计算资源、调整资源组配置与分配方式。 |
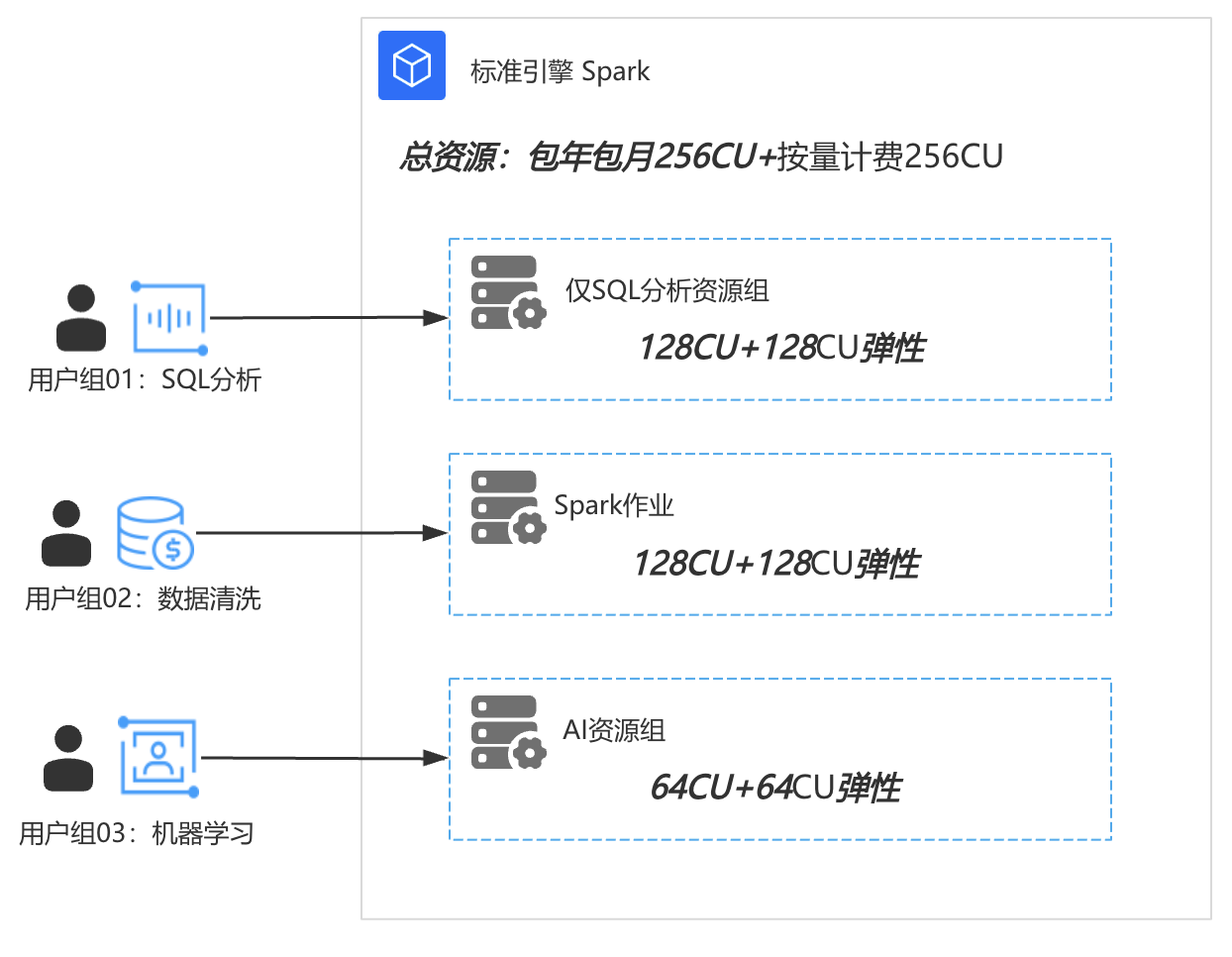
场景:通过合理规划任务的分时运行,实现资源利用最大化
某企业现需要购买计算资源给三个部门分配使用,他们分别需要进行:交互式 SQL 分析与 Spark 批作业任务。企业有较高的成本控制的要求,故希望销售团队可以出给出一个合理的购买方案建议:在资源利用最大的基础下,即能够保障资源可以合理分配给三个部门使用,且不能出现任务失败的情况。
推荐方案:
1. 针对交互式 SQL 任务,需要根据每天需要运行的任务个数和复杂度,评估交互式资源组的运行时间、最小资源数量和弹性情况。
该部门经过分析得出:在每天9点到5点跑交互式SQL,根据SQL任务最大的并发数和资源需求数,确定该资源组需要使用的最大规格128CU,可以配置资源使用为4CU~128CU。其中4CU为资源组资源最小值。
2. 针对作业任务,需要根据任务的运行时效去评估需要的资源。
如该企业,部门B有一个定时任务,每个小时跑一次,若要在当前小时运行结束,至少使用128CU资源才能保证任务按时完成,那么可以配置作业的资源为4cu~128CU。
部门C也有任务每天跑一次,只需要在凌晨运行,但必须在早上八点前运行完成,需要资源256CU。
这里发现:
部门 A 和 B 的任务时间有重叠,所以引擎最大资源需要配置:128 + 128 = 256CU
而部门 B 和部门 C 的任务时间也有重叠,为了保证任务按时完成,需要配置最大资源为:128 + 256 = 384CU
故销售根据每天运行的时间使用情况,确认给出:“128CU包年包月 + 128CU弹性计费”的资源购买建议。
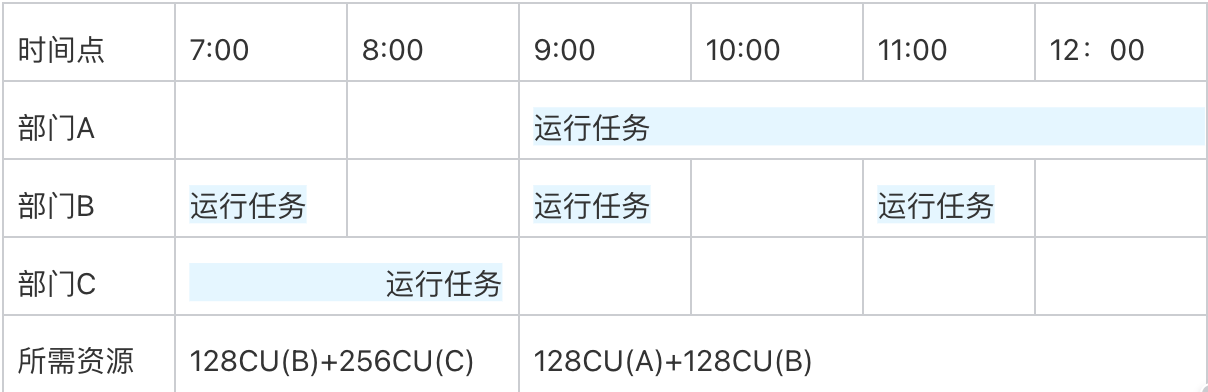
如何进行成本追踪
方式一:通过分账实现成本追踪
如何所示:通过为引擎打上不同的标签后,标签 A 可以看到引擎1、2的费用统计,B 可以看到引擎3的费用,C 可以看到引擎2、3的费用统计。
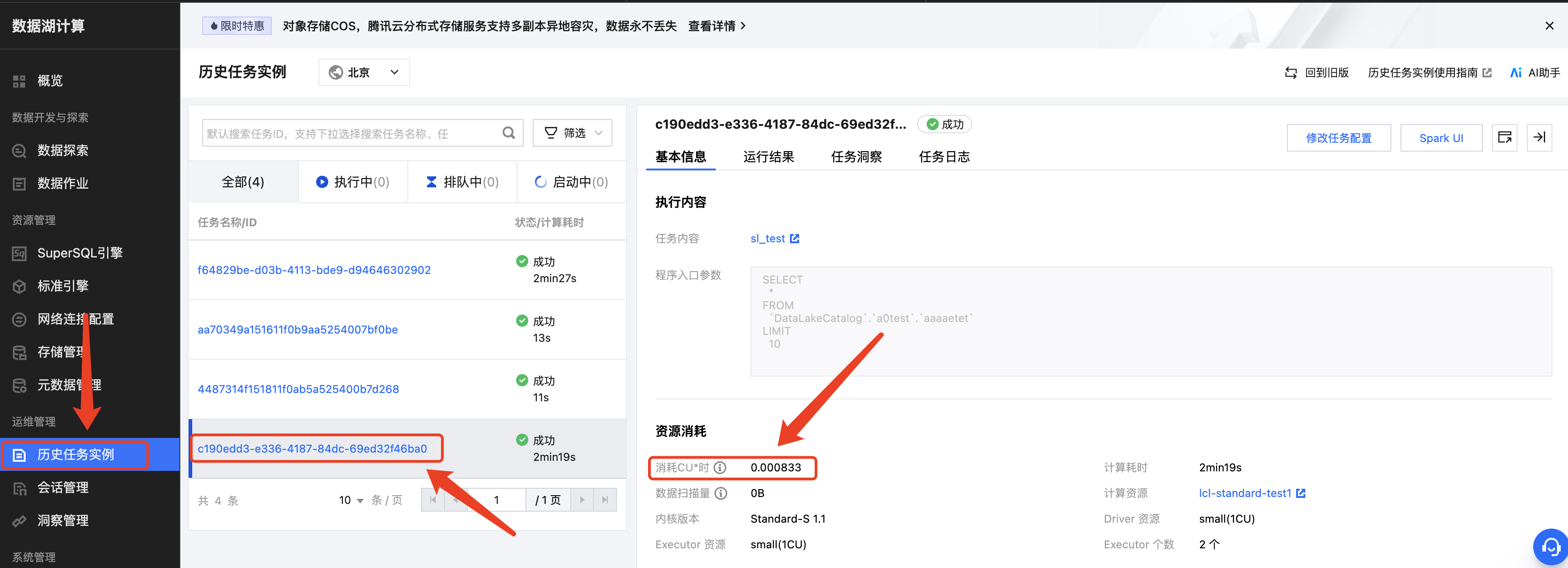
方式二:通过任务的洞察功能实现成本追踪
说明:
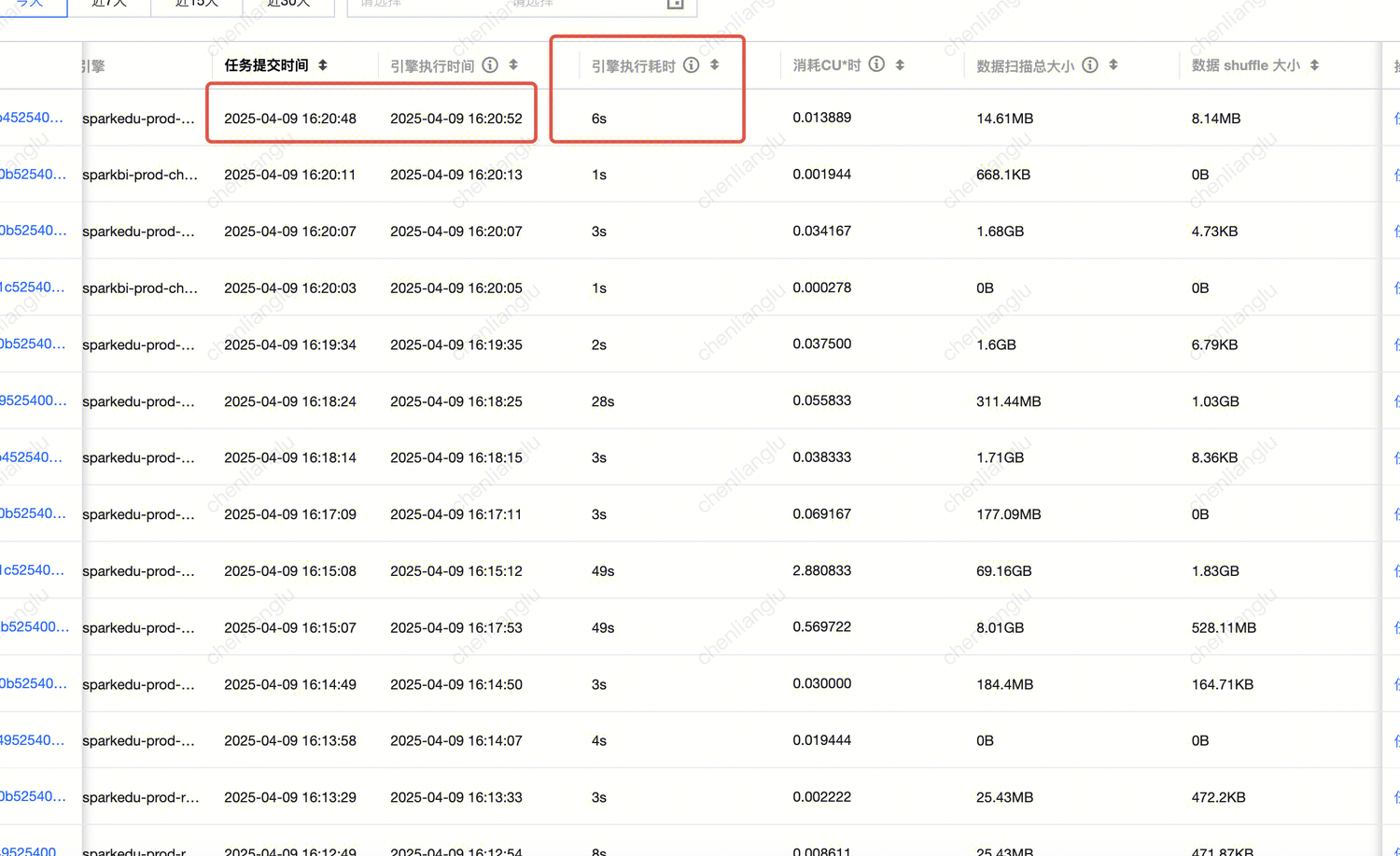
1. CU消耗*时:含为参与计算所用 Spark Executor 每个 core 的 CPU 执行时长总和,单位小时。
2. 该资源消耗是该任务实际占用资源产生的消耗,没有包含资源拉起、资源组空闲等时间统计,故该值会远小于资源组的总消耗,无法和计费侧的数据完全一致。该消耗值推荐用于分析单个任务实际使用的资源量,用于单个任务的优化,或者进行用量大小等成本分析。
如何通过任务治理,提升任务完成时效,达到成本优化
适用场景 | 1. 对 Spark 引擎整体运行状况的洞察分析,例如:引擎下各任务运行时的资源抢占情况,引擎内资源使用情况,引擎执行时长,数据扫描大小,数据shuffle 大小等都有直观的展示与分析。 2. 自助排查分析任务运行情况,例如:可对众多任务按照耗时筛选排序,快速找到有问题的大任务,定位 Spark 任务运行缓慢或者失败的原因,如资源抢占,shuffle 异常,磁盘不足等情况,都有清晰的定位。 |
重点指标 | 1. 引擎执行时间:Spark 引擎执行的第一个 Task 时间(即任务第一次抢占 CPU 开始执行的时间)。 2. 引擎内执行耗时:反映真正用于计算所需的耗时,即从 Spark 任务第一个 Task 开始执行到任务结束之间的耗时。 3. 排队耗时:从任务提交到开始执行第一个 Spark Task 之间的耗时,其中耗时可能有:引擎第一次执行的冷启动耗时、配置任务并发上限导致的排队时间 、引擎内因资源打满导致的等待 executor 资源的耗时、资源组无法分配到资源导致的排队耗时。 4. 消耗 CU * 时:统计参与计算所用 Spark Executor 每个 core 的 CPU 执行时长总和,单位CU*小时。 |
场景1:通过任务问题自动分析,快速定位问题,提升任务运行时效
任务质量参差不齐,众多任务难以运维,导致集群资源利用率低下。
导致任务的运行慢的因素主要有:数据倾斜,shuffle 并发度不够,长尾任务拖慢整体执行时间等。通过数据湖计算DLC 任务洞察 功能支持对任务运行过程中遇到的部分问题进行分析,并提出优化方案。在时间有限的情况下,可优先找到头部大任务,优化效果收益更好。
1. 例如按照引擎执行耗时排序(或者 消耗 CU * 时耗时排序)后,筛选有问题的任务。
2. 例如:Spark shuffle 阶段是影响任务执行速度和整体集群稳定关键因素,针对大 shuffle 数据量的任务进行定向优化收益会比较明显。具体操作:可以按任务 shuffle 大小排序,筛选 shuffle 异常任务(成功任务内部也可能会存在 shuffle 失败重试的情况),或者定向优化头部大 shuffle 任务对整体集群消耗收益都比较好。
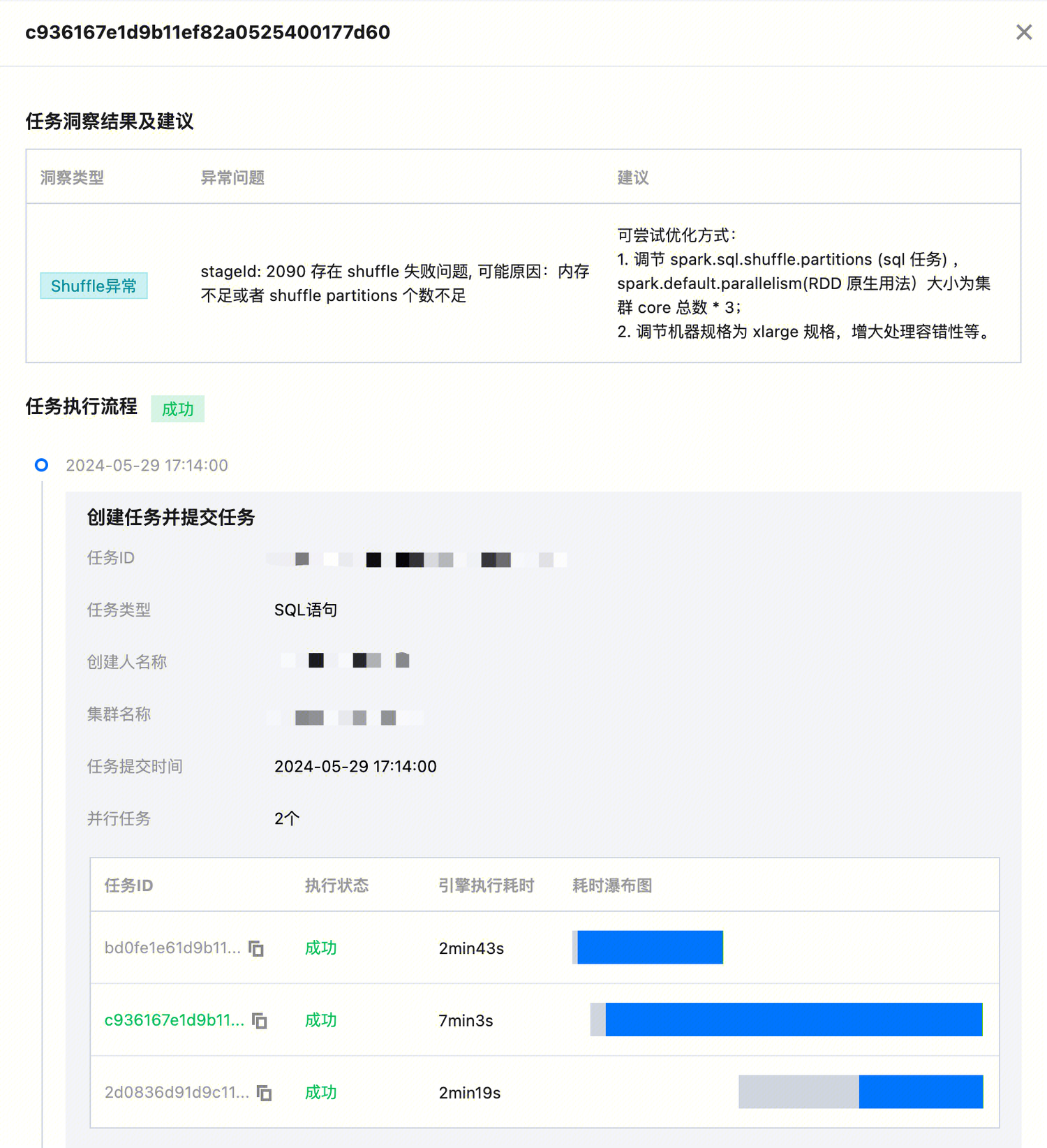
可重点关注以下指标:
洞察类型 | 算法描述(正持续改进和新增算法) |
资源抢占 | sql 开始执行的 task 延迟时间>stage 提交时间1分钟,或延迟时长超过总运行时长的20%(不同运行时长和数据量的任务,阈值公式会有动态调整) |
shuffle 异常 | stage 执行出现 shuffle 相关错误栈信息 |
慢 task | stage 中 task 时长 > stage 里其他 task 平均时长的2倍(不同运行时长和数据量的任务,阈值公式会有动态调整) |
数据倾斜 | task shuffle 数据 > task 平均 shuffle 数据大小的2倍 (不同运行时长和数据量的任务,阈值公式会有动态调整) |
磁盘或内存不足 | stage 执行错误栈信息中包含了 oom 或者 磁盘不足的信息 或者 cos 带宽限制报错 |
输出较多小文件 | (该洞察类型的收集需 Spark 引擎内核升级至 2024.11.16 之后的版本) 参考列表中的指标 "输出小文件个数" ,满足下述一个条件则判定为 "存在输出较多小文件" : 1. 分区表,若某个分区写出的小文件超过 200 个 2. 非分区表,输出小文件总数超过 1000 个 3. 分区、非分区表写出文件超过 3000 个,平均文件大小小于 4MB |
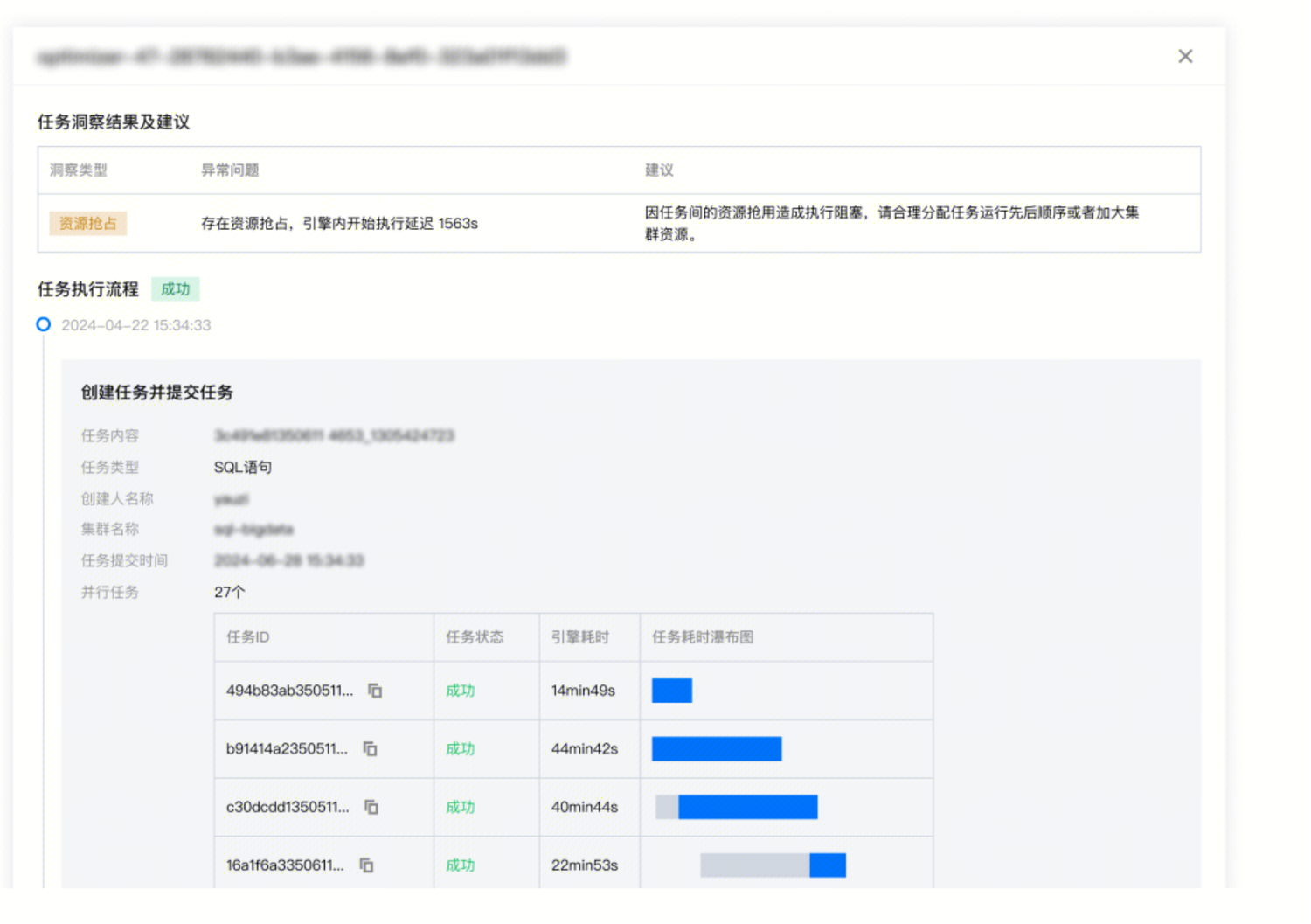
场景2:通过引擎洞察,快速分析资源抢占情况,合理安排任务运行数量,提升任务运行时效
执行慢并不等于计算本身慢,在集群资源有限的情况下,容易造成任务会互相争抢资源,通过洞察管理功能,参考引擎内执行耗时和排队耗时两个指标,找到互相影响的任务后,合理调整任务排队规划。
例如下图,任务提交,引擎不一定会开始执行,从任务提交到开始执行第一个 Spark Task 之间可能包含:引擎第一次执行的冷启动耗时、配置任务并发上限导致的排队耗时 、引擎内因资源打满导致的等待 executor 资源的耗时、生成和优化 Spark 执行计划耗时等。
当集群资源不足时,这种前期等待资源耗时会更加明显。
同时任务洞察也支持对资源抢占的自动发现,如下图。并且可以查看和该任务并发的其他任务是否在抢占资源。
文档反馈