使用 Apache Airflow 调度 DLC 引擎提交任务
Download
聚焦模式
字号
本文介绍 DLC 对 Apache Airflow 调度工具的支持,并提供示例来演示如何使用 Apache Airflow 运行 DLC 不同种类的引擎任务。
背景信息
Apache Airflow 是一款由 Airbnb 开源的调度工具,用 Python 编写,采用有向无环图(DAG)的方式来定义和调度一组有依赖关系的作业。它支持 Python 编写的子作业,并提供多种操作器(Operators)来执行任务,如 Bash 命令、Python 函数、SQL 查询和 Spark 作业等,具备很高的灵活性和可扩展性。Apache Airflow 广泛应用于数据工程、数据处理和工作流自动化等领域。借助 Apache Airflow 提供的丰富功能和可视化界面,用户可以轻松监控和管理工作流的状态和执行情况。更多关于 Apache Airflow 信息,请参见 Apache Airflow。
前提条件
1. Apache Airflow 环境准备。
2. 安装并启动 Apache Airflow,更多安装及启动 Apache Airflow 操作,请参见Apache Airflow 快速入门。
3. 安装 jaydebeapi 依赖包, pip install jaydebeapi。
4. 数据湖计算 DLC 环境准备。
5. 开通数据湖计算 DLC 引擎服务。
6. 如使用标准 Spark 引擎,准备好 Hive JDBC 驱动,点击下载 hive-jdbc-3.1.2-standalone.jar。
7. 如使用标准 Presto 引擎,准备好 Presto JDBC 驱动,点击下载 presto-jdbc-0.284.jar。
8. 如使用 SuperSQL 引擎,准备好 DLC JDBC 驱动,点击下载 JDBC 驱动。
说明:
presto 引擎已下线,仅供存量用户使用。
关键步骤
创建 Connection 和调度任务
在 Apache Airflow 工作目录下新建 dags 目录,在 dags 目录下新建调度脚本并保存为.py 文件,例如本文建立调度脚本/root/airflow/dags/airflow-dlc-test.py 如下所示:
import timefrom datetime import datetime, timedeltaimport jaydebeapifrom airflow import DAGfrom airflow.operators.python_operator import PythonOperatorjdbc_url='jdbc:dlc:dlc.tencentcloudapi.com?task_type=SparkSQLTask&database_name={dataBaseName}&datasource_connection_name={dataSourceName}®ion={region}&data_engine_name={engineName}'user = 'xxx'pwd = 'xxx'dirver = 'com.tencent.cloud.dlc.jdbc.DlcDriver'jar_file = '/root/airflow/jars/dlc-jdbc-2.5.3-jar-with-dependencies.jar'def createTable():sqlStr = 'create table if not exists db.tb1 (c1 int, c2 string)'conn = jaydebeapi.connect(dirver, jdbc_url, [user, pwd], jar_file)curs = conn.cursor()curs.execute(sqlStr)rows = curs.rowcount.realif rows != 0:result = curs.fetchall()print(result)curs.close()conn.close()def insertValues():sqlStr = "insert into db.tb1 values (111, 'this is test')"conn = jaydebeapi.connect(dirver,jdbc_url, [user, pwd], jar_file)curs = conn.cursor()curs.execute(sqlStr)rows = curs.rowcount.realif rows != 0:result = curs.fetchall()print(result)curs.close()conn.close()def selectColums():sqlStr = 'select * from db.tb1'conn = jaydebeapi.connect(dirver, jdbc_url, [user, pwd], jar_file)curs = conn.cursor()curs.execute(sqlStr)rows = curs.rowcount.realif rows != 0:result = curs.fetchall()print(result)curs.close()conn.close()def get_time():print('当前时间是:', datetime.now().strftime('%Y-%m-%d %H:%M:%S'))return time.time()default_args = {'owner': 'tencent', # 拥有者名称'start_date': datetime(2024, 11, 1), # 第一次开始执行的时间,为 UTC 时间'retries': 2, # 失败重试次数'retry_delay': timedelta(minutes=1), # 失败重试间隔}dag = DAG(dag_id='airflow_dlc_test', # DAG id ,必须完全由字母、数字、下划线组成default_args=default_args, # 外部定义的 dic 格式的参数schedule_interval=timedelta(minutes=1), # 定义DAG运行的频率,可以配置天、周、小时、分钟、秒、毫秒catchup=False # 执行DAG时,将开始时间到目前所有该执行的任务都执行,默认为True)t1 = PythonOperator(task_id='create_table',python_callable=createTable,dag=dag)t2 = PythonOperator(task_id='insert_values',python_callable=insertValues,dag=dag)t3 = PythonOperator(task_id='select_values',python_callable=selectColums,dag=dag)t4 = PythonOperator(task_id='print_time',python_callable=get_time,dag=dag)t1 >> t2 >> [t3, t4]
参数说明:
参数 | 说明 |
jdbc_url | |
user | SecretId |
pwd | SecretKey |
dirver | |
jar_file |
运行调度任务
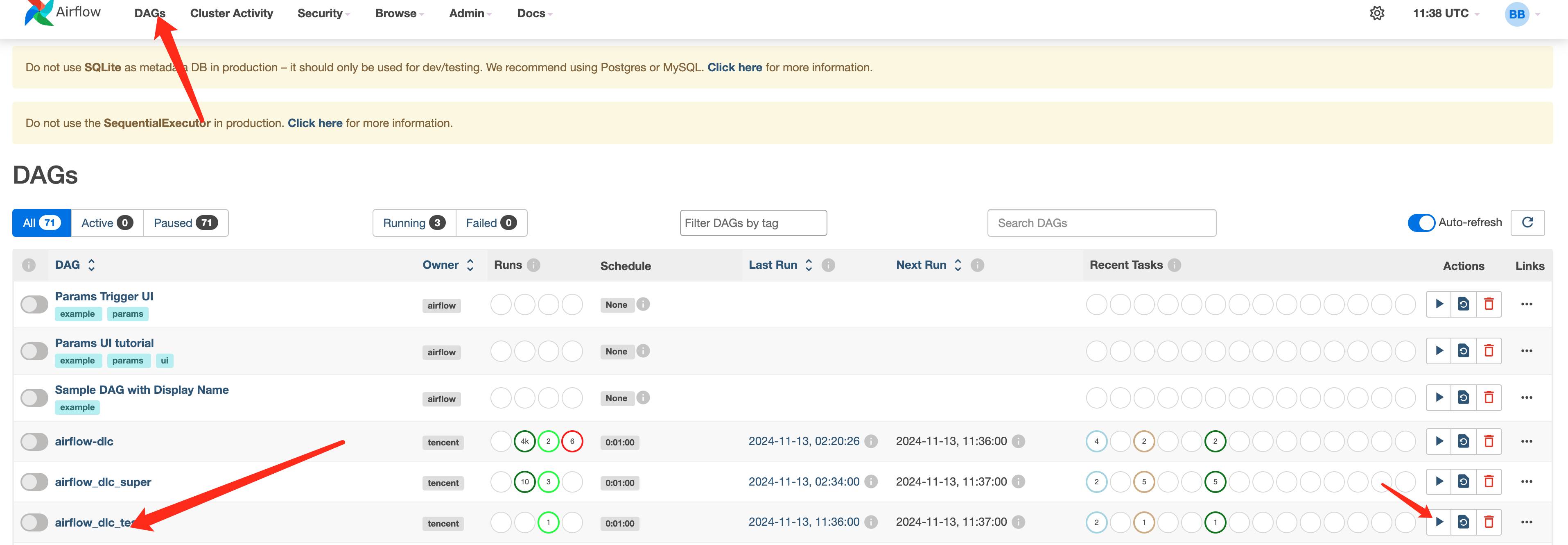
您可以进入 Web 界面,在 DAGs 页签,查找到提交的调度流程并启动调度。
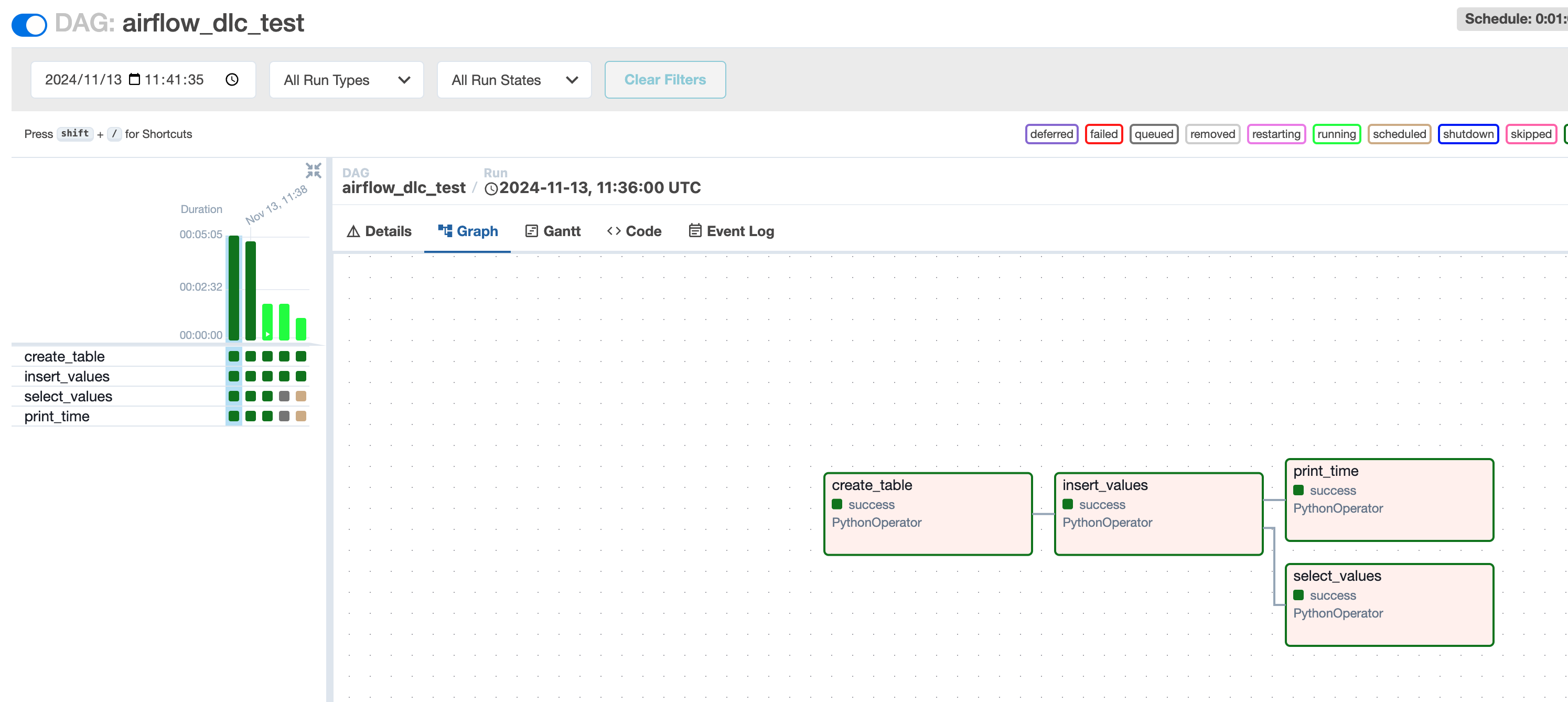
查看任务运行结果
文档反馈