标准引擎介绍
Download
聚焦模式
字号
标准引擎是 DLC 提供的一类计算资源,帮助用户快速启动一定规格的计算集群。标准引擎提供了对原生语法和行为的全面支持,这使得熟悉大数据生态的用户能够更加迅速地上手并轻松使用。
标准引擎类型
用户可以根据需求选择使用不同的标准引擎内核来应对不同的使用场景。标准引擎分为以下类型:
Spark:适用于稳定高效的离线 SQL 任务, Spark 原生的流式/批式数据作业处理。
Presto:适用于敏捷、快速的交互式查询分析。
网关:网关是一类特殊的标准引擎,基于原生 Kyuubi 实现。网关用于用户连接 Spark/Presto 计算引擎并提交任务,是使用其他计算引擎的前置条件。
引擎弹性
当前只有包年包月 Spark 标准引擎支持配置按量计费资源弹性。

如图所示,任务和资源组会优先使用包年包月部分资源,如果用户提交的任务将包年包月部分的资源耗尽,继续提交任务将会使用配置的按量计费弹性资源。图中任务03分配的资源用完包年包月部分资源后还不够,会继续使用按量计费部分的资源。
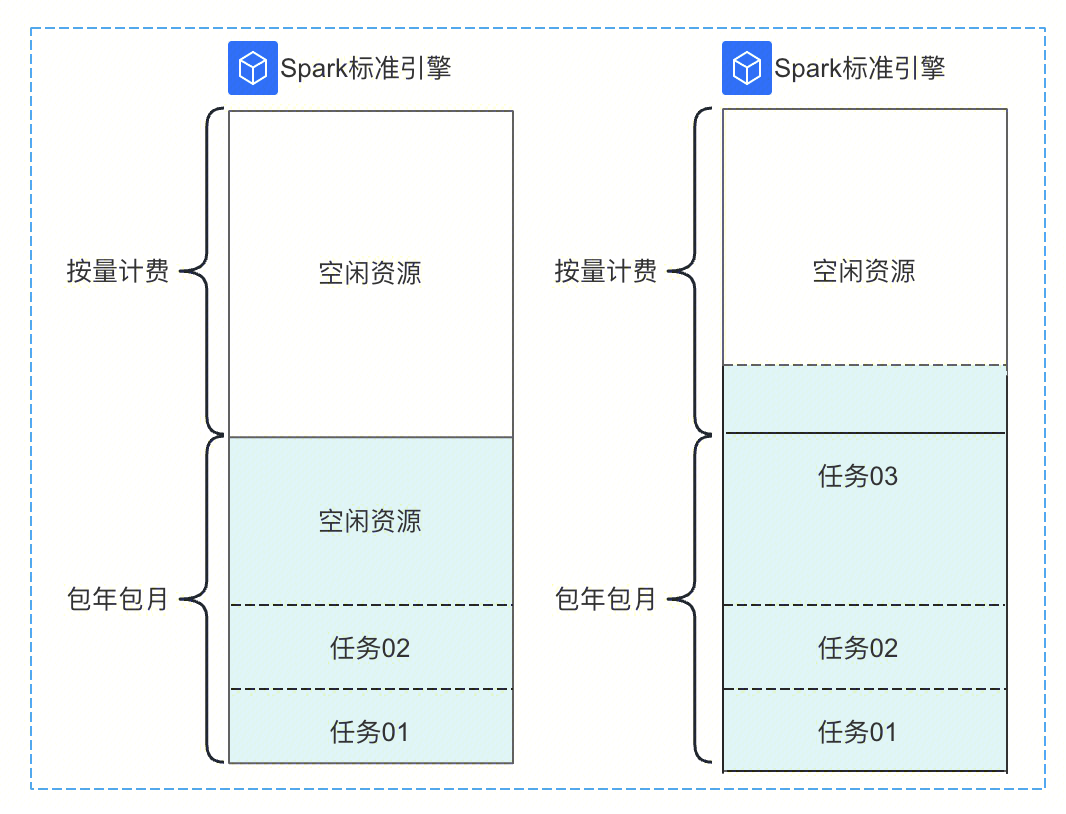
注意:
1. 按量计费弹性资源根据实际使用的计算资源进行计费。
2. 启动的任务和资源组如果调度到了按量计费资源上,就算包年包月部分资源释放,资源组也会继续使用按量部分资源,重启资源组后才会调度到包年包月资源上。
3. 单个 Spark 标准引擎能够设置的弹性资源上限不超过包年包月资源数,即128CU 包年包月引擎最多设置128CU 弹性资源。如果您需要设置更多弹性资源,请通过工单联系我们。
标准引擎相关术语
术语 | 说明 |
集群类型 | |
弹性集群规格 | 包年包月 Spark 引擎允许用户配置弹性规格。在包年包月资源包耗尽后,系统将根据用户配置自动弹出按量计费的资源使用。 |
网关名称 | 网关的名字,全局唯一。不能和其他网关,计算引擎同名。 |
引擎名称 | 引擎的名字,全局唯一。不能和其他网关,计算引擎同名。 |
引擎类型 | 标准引擎类型,分为 Presto 引擎和 Spark 引擎,网关也是一类特殊的标准引擎。 |
引擎状态 | 标准引擎的状态,集群根据当前运行情况,分为启动中、运行、就绪、暂停、暂停中、变配中、隔离、隔离中、恢复中九个状态。 启动中:该集群资源正在被拉起,按量计费的引擎此时不计费。启动中的集群无法被数据计算选中使用。 运行:该集群正在运行,可被数据计算选中使用。 就绪:和运行一样的状态,代表引擎可以使用。 暂停:该集群暂停使用,无法被数据计算选中使用。 暂停中:该集群正在切换为暂停状态,会影响正在运行的任务,无法被数据计算选中使用。 变配中:该集群正在进行配置变更,配置变更期间将无法被数据计算使用。 隔离:由于账号欠费导致的集群被隔离,无法被数据计算选中使用。 隔离中:由于账号欠费导致,集群正在切换为隔离状态,会影响正在运行的任务,无法被数据计算选中使用。 恢复中:账号通过充值不再欠费后,集群由隔离状态恢复到运行状态的过程,无法被数据计算选中使用 |
资源组数量 | 标准 Spark 下当前的资源组数量。 |
使用资源/总资源 | 引擎当前使用资源和引擎可用总资源的数量。 总资源数量为常驻资源数加弹性资源数。 使用资源包含了 DLC 部署服务系统占用资源统计。 统计的数据有一定的延时。 |
付费类型 | 付费类型分为包年包月和按量计费。 网关只支持包年包月模式。 标准 Spark 和 Presto 引擎支持包年包月和按量计费。 |
是否自动续费 | 包年包月引擎即将到期是否会自动续费。 |
引擎规模 | 引擎可用资源总量,单位 CU。 其中包年包月的引擎规模包含引擎常驻规格和按量计费的弹性规格。 注意: 1. 包年包月引擎购买的时候一次性收费,引擎状态不影响账单费用; 2. 按量计费引擎根据用户的使用量收费: 标准 Presto 引擎挂起后不收费,运行中收费。其中引擎启动中会产生部分费用。 标准 Spark 引擎就绪状态不会产生费用,只有用户提交任务或者启动资源组运行,才会产生费用。 |
文档反馈