DLC JDBC 访问
Download
聚焦模式
字号
说明:
presto 引擎已下线,仅供存量用户使用。
环境准备
依赖:JDK 1.8
JDBC 下载:点击下载 JDBC 驱动
连接 DLC
1. 加载 DLC JDBC 驱动
Class.forName("com.tencent.cloud.dlc.jdbc.DlcDriver");
2. 通过 DriverManager 创建 Connection
Connection cnct = DriverManager.getConnection(url, secretId, secretKey);
url 格式
jdbc:dlc:<dlc_endpoint>?task_type=SQLTask&database_name=abc&datasource_connection_name=DataLakeCatalog®ion=ap-nanjing&data_engine_name=spark-cu&result_type=COS&read_type=Stream
JDBC 链接串参数说明:
参数 | 必填 | 说明 |
dlc_endpoint | 是 | DLC 服务的 Endpoint,固定为 dlc.tencentcloudapi.com |
datasource_connection_name | 是 | 数据源连接名称,对应 DLC 的数据目录 |
task_type | 是 | 任务类型。 Presto 引擎填写:SQLTask SparkSQL 引擎填写:SparkSQLTask Spark 作业引擎填写:BatchSQLTask |
database_name | 否 | 数据库名称 |
region | 是 | 地域,目前 DLC 服务支持 ap-nanjing, ap-beijing, ap-guangzhou,ap-shanghai, ap-chengdu,ap-chongqing, na-siliconvalley, ap-singapore, ap-hongkong |
data_engine_name | 是 | 数据引擎名称 |
secretId | 是 | 腾讯云 API 密钥管理中的 SecretId |
secretKey | 是 | 腾讯云 API 密钥管理中的 SecretKey |
result_type | 否 | 默认为 Service。如果您对获取结果的速度有更高要求,可以设置为 COS。 Service:通过 DLC 接口获取结果 COS:通过 COS 客户端获取结果 |
read_type | 否 | Stream:流式从 COS 获取结果 DownloadSingle:单个文件下载到本地获取结果 默认值为 Stream.只有当 result_type 为 COS,该值才有意义。 下载文件位置为/tmp 临时目录,请确保该目录有读写权限,数据读取完成会自动删除。 |
执行查询
Statement stmt = cnct.createStatement();ResultSet rset = stmt.executeQuery("SELECT * FROM dlc");while (rset.next()){// process the results}rset.close();stmt.close();conn.close();}rset.close();stmt.close();conn.close();
语法支持
目前 JDBC 可以使用的语法与 DLC 标准语法保持一致。
实例代码
库表操作
import java.sql.*;public class MetaTest {public static void main(String[] args) throws SQLException {try {Class.forName("com.tencent.cloud.dlc.jdbc.DlcDriver");} catch (ClassNotFoundException e) {e.printStackTrace();return;}Connection connection = DriverManager.getConnection("jdbc:dlc:<dlc_endpoint>?task_type=<task_type>&database_name=<database_name>&datasource_connection_name=DataLakeCatalog®ion=<region>&data_engine_name=<data_engine_name>&result_type=<result_type>","<secret_id>","secret_key");Statement statement = connection.createStatement();String dbName = "dlc_db1";String createDatabaseSql = String.format("CREATE DATABASE IF NOT EXISTS %s", dbName);statement.execute(createDatabaseSql);String tableName = "dlc_t1";String wholeTableName = String.format("%s.%s", dbName, tableName);String createTableSql =String.format("CREATE EXTERNAL TABLE %s ( "+ " id string , "+ " name string , "+ " status string , "+ " type string ) "+ "ROW FORMAT SERDE "+ " 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' "+ "STORED AS INPUTFORMAT "+ " 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' "+ "OUTPUTFORMAT "+ " 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' "+ "LOCATION\\\\n"+ " 'cosn://<bucket_name>/<path>' ",wholeTableName);statement.execute(createTableSql);// get meta dataDatabaseMetaData metaData = connection.getMetaData();System.out.println("product = " + metaData.getDatabaseProductName());System.out.println("jdbc version = "+ metaData.getDriverMajorVersion() + ", "+ metaData.getDriverMinorVersion());ResultSet tables = metaData.getTables(null, dbName, tableName, null);while (tables.next()) {String name = tables.getString("TABLE_NAME");System.out.println("table: " + name);ResultSet columns = metaData.getColumns(null, dbName, name, null);while (columns.next()) {System.out.println(columns.getString("COLUMN_NAME") + "\\\\t" +columns.getString("TYPE_NAME") + "\\\\t" +columns.getInt("DATA_TYPE"));}columns.close();}tables.close();statement.close();connection.close();}}
数据查询
import java.sql.*;public class DataTest {public static void main(String[] args) throws SQLException {try {Class.forName("com.tencent.cloud.dlc.jdbc.DlcDriver");} catch (ClassNotFoundException e) {e.printStackTrace();return;}Connection connection = DriverManager.getConnection("jdbc:dlc:<dlc_endpoint>?task_type=<task_type>&database_name=<database_name>&datasource_connection_name=DataLakeCatalog®ion=<region>&data_engine_name=<data_engine_name>&result_type=<result_type>","<secret_id>","secret_key");Statement statement = connection.createStatement();String sql = "select * from dlc_test";statement.execute(sql);ResultSet rs = statement.getResultSet();while (rs.next()) {System.out.println(rs.getInt(1) + ":" + rs.getString(2));}rs.close();statement.close();connection.close();}}
数据库客户端
您可以将 DLC 的 JDBC 驱动包加载到 SQL 客户端,连接到 DLC 服务进行查询。
前置条件
1. 已开通数据湖计算 Data Lake Compute 服务。
2. 已下载上文中的 JDBC 驱动包。
3. 已下载并安装 SQL Workbench/J。
操作步骤
1. 通过 JDBC 驱动包创建 DLC Driver。
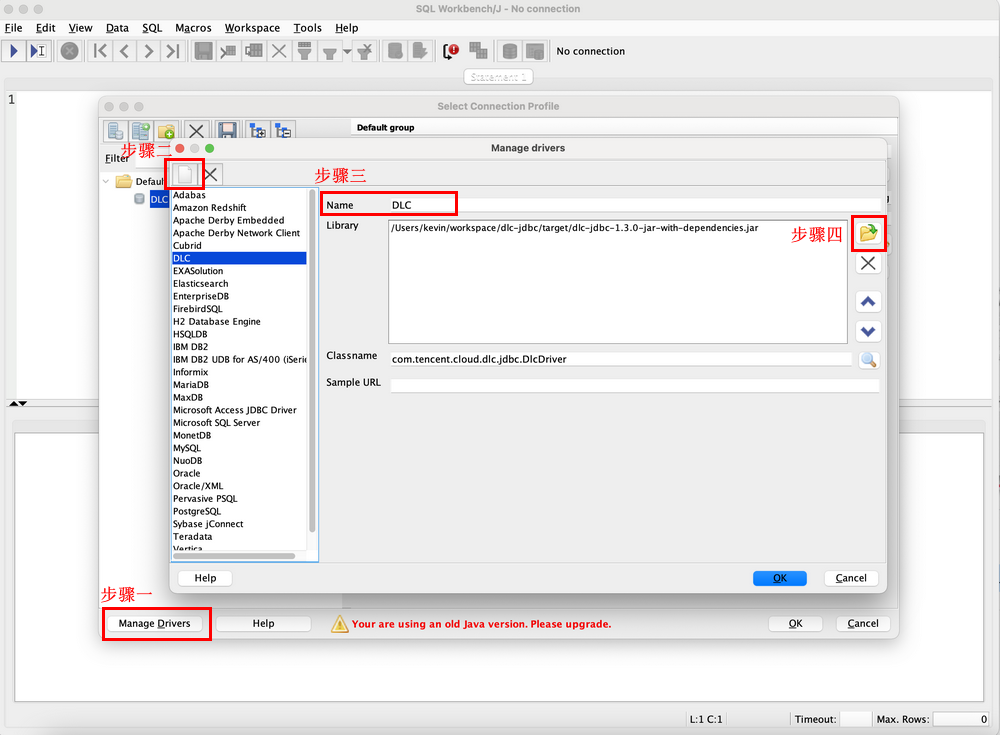
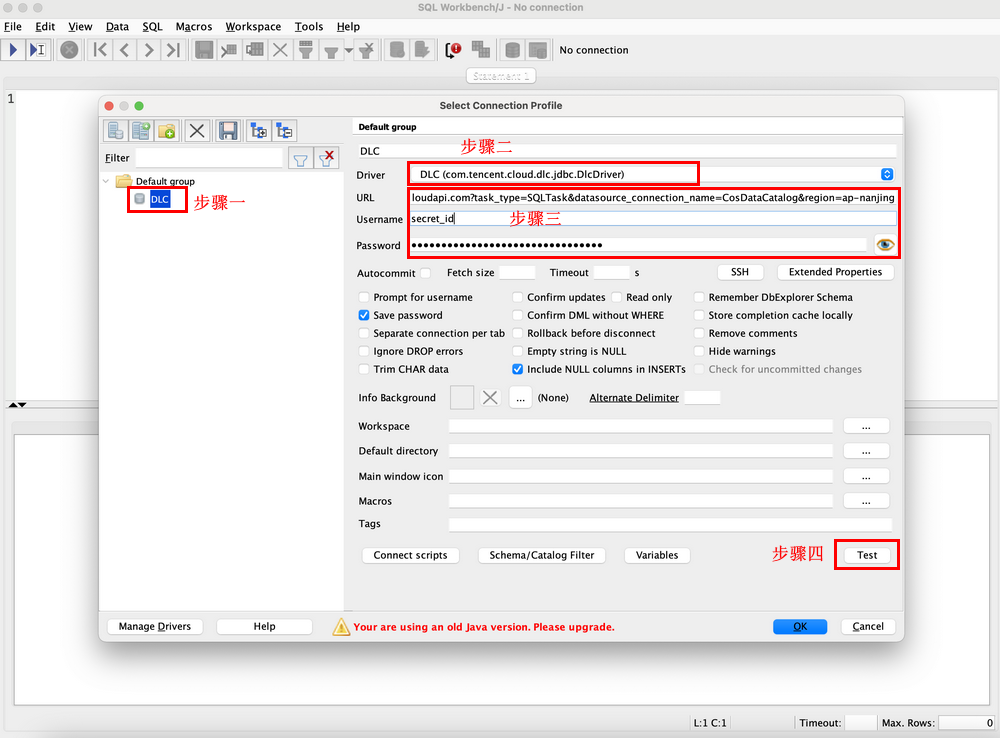
2. 连接 DLC,填入如下参数,单击 test,测试通过后,完成与 DLC 的连接。
Name:连接名称,用于标识与 DLC 的连接。
Username:对应于腾讯云用户的 secret_id。
Password:对应于腾讯云用户的 secret_key。
URL:用于连接 DLC 的 URL,格式和上文中通过 JDBC 创建连接的 URL 一致。
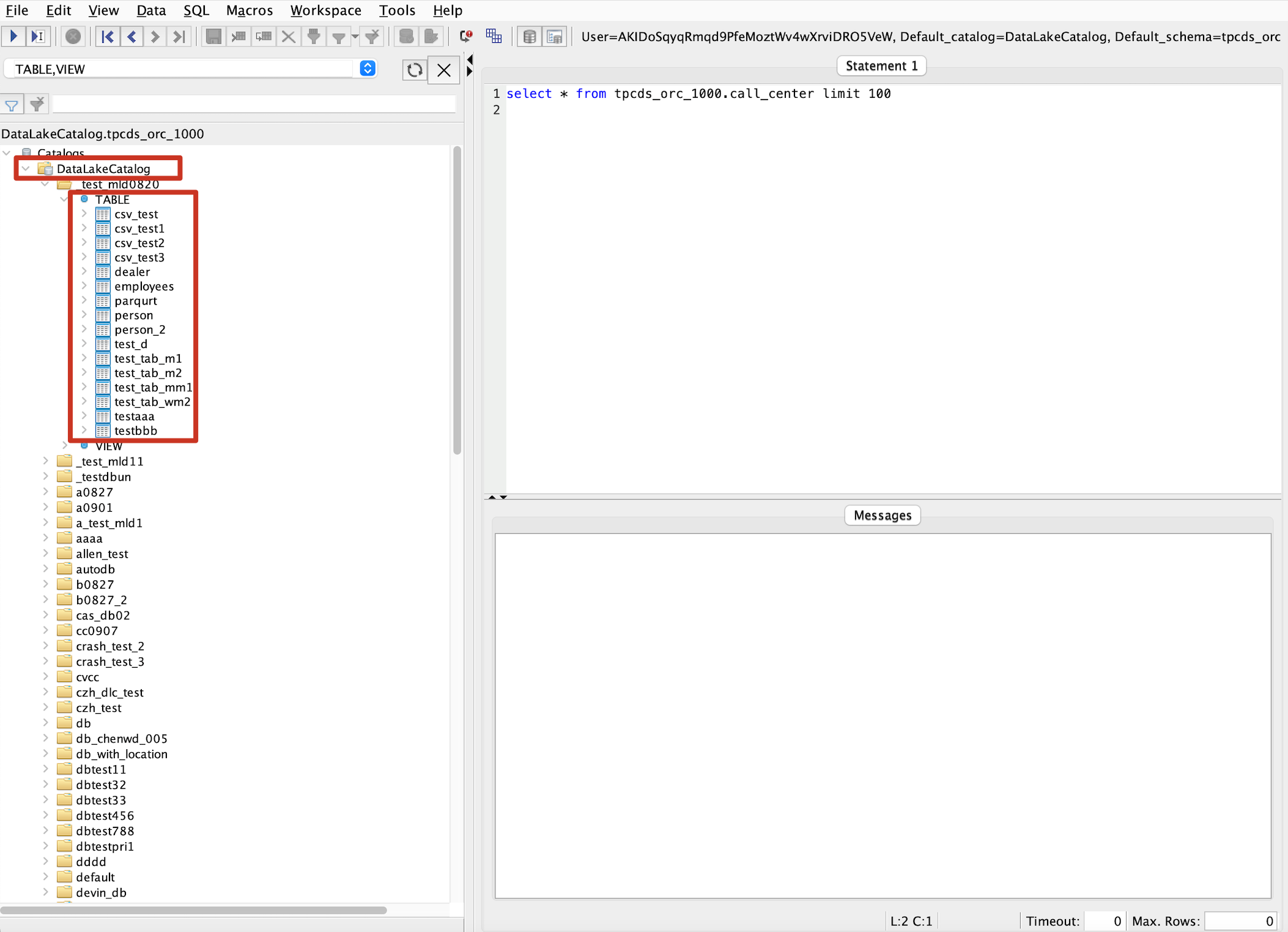
3. 查看库表信息。
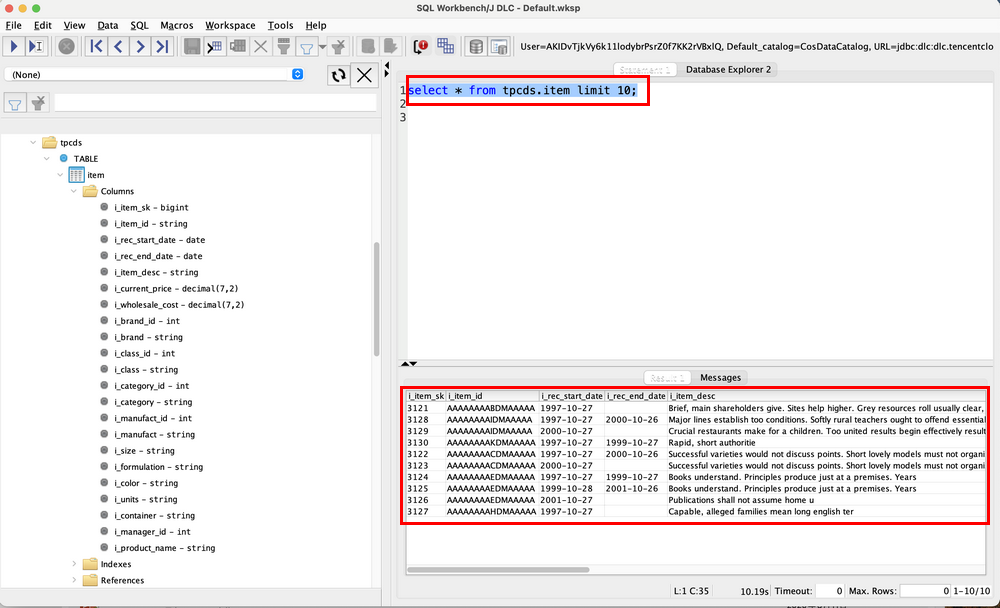
4. 查询数据。
文档反馈