Hive JDBC 访问
Download
聚焦模式
字号
支持引擎类型
标准Spark引擎
环境准备
依赖:JDK 1.8
JDBC 下载:点击下载 hive-jdbc-3.1.2-standalone.jar
连接标准 Spark 引擎
创建服务访问链接
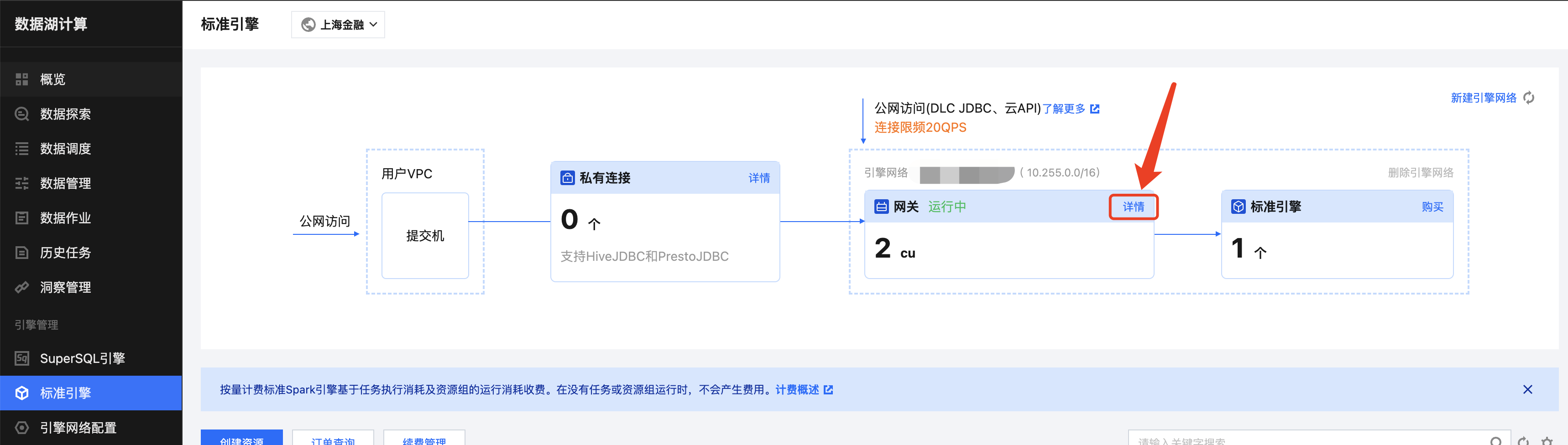
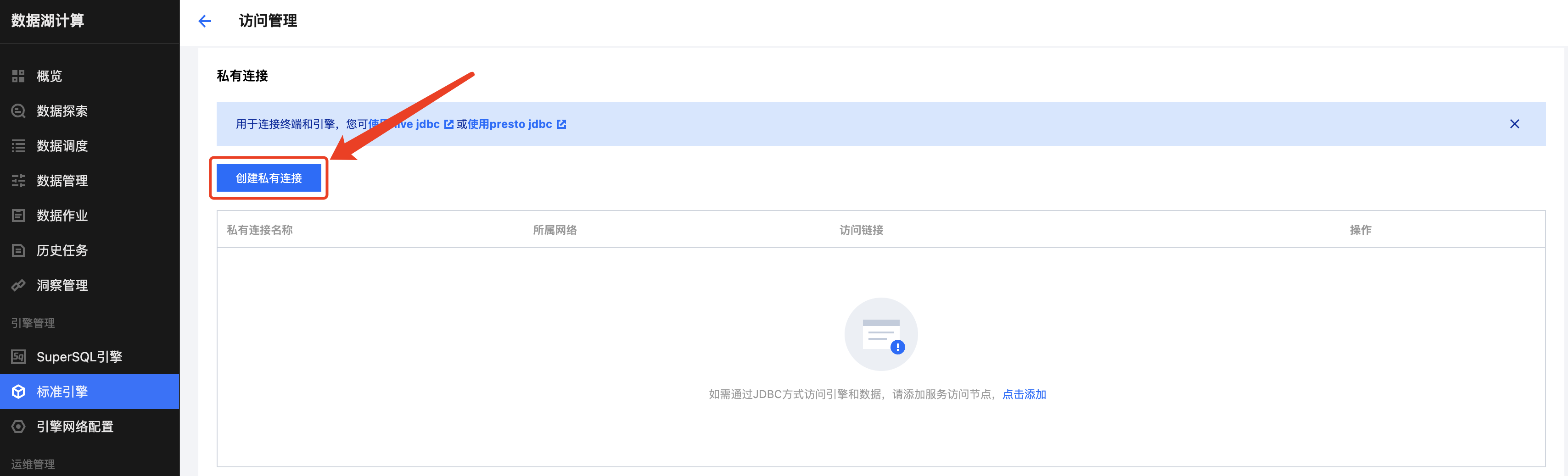
点击创建私有连接,选择提交机所在的 VPC 和子网,单击创建后生成两个访问链接,分别为 Hive2 和 Presto 协议,链接标准 Spark 引擎使用 Hive2 协议,如下图所示。
注意:
创建私有连接会打通引擎网络和所选 VPC 之间的网络。提交机可以是所选 VPC 下任意可以登录使用的服务器,仅用于任务提交使用。如果所选的VPC 下没有提交机,可以新建一个服务器作为提交机。
jdbc:hive2://{endpoint}:10009/?spark.engine={DataEngineName};spark.resourcegroup={ResourceGroupName};secretkey={SecretKey};secretid={SecretId};region={Region};kyuubi.engine.type=SPARK_SQL;kyuubi.engine.share.level=ENGINE
加载 JDBC 驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
通过 DriverManager 创建 Connection
jdbc:hive2://{endpoint}:10009/?spark.engine={DataEngineName};spark.resourcegroup={ResourceGroupName};secretkey={SecretKey};secretid={SecretId};region={Region};kyuubi.engine.type=SPARK_SQL;kyuubi.engine.share.level=ENGINEProperties properties = new Properties();properties.setProperty("user", {AppId});Connection cnct = DriverManager.getConnection(url, properties);
JDBC 连接串参数说明
参数 | 必填 | 说明 |
spark.engine | 是 | 标准 Spark 引擎名称 |
spark.resourcegroup | 否 | 标准 Spark 引擎资源组名称,不指定则创建临时资源 |
secretkey | 是 | 腾讯云 API 密钥管理中的 SecretKey |
secretid | 是 | 腾讯云 API 密钥管理中的 SecretId |
region | 是 | 地域,目前 DLC 服务支持 ap-nanjing, ap-beijing, ap-beijing-fsi, ap-guangzhou,ap-shanghai, ap-chengdu,ap-chongqing, na-siliconvalley, ap-singapore, ap-hongkong, na-ashburn, eu-frankfurt, ap-shanghai-fsi |
kyuubi.engine.type | 是 | 固定填:SparkSQLTask |
kyuubi.engine.share.level | 是 | 固定填:ENGINE |
user | 是 | 用户 APPID |
数据查询完整示例
import org.apache.hive.jdbc.HiveStatement;import java.sql.*;import java.util.Properties;public class TestStandardSpark {public static void main(String[] args) throws SQLException {try {Class.forName("org.apache.hive.jdbc.HiveDriver");} catch (ClassNotFoundException e) {e.printStackTrace();return;}String url = "jdbc:hive2://{endpoint}:10009/?spark.engine={DataEngineName};spark.resourcegroup={ResourceGroupName};secretkey={SecretKey};secretid={SecretId};region={Region};kyuubi.engine.type=SPARK_SQL;kyuubi.engine.share.level=ENGINE";Properties properties = new Properties();properties.setProperty("user", {AppId});Connection connection = DriverManager.getConnection(url, properties);HiveStatement statement = (HiveStatement) connection.createStatement();String sql = "SELECT * FROM dlc_test LIMIT 100";statement.execute(sql);ResultSet rs = statement.getResultSet();while (rs.next()) {System.out.println(rs.getInt(1) + ":" + rs.getString(2));}rs.close();statement.close();connection.close();}}
编译完成后,您可以将 jar 包提交到提交机上执行。
文档反馈