DLC 原生表操作配置
Download
聚焦模式
字号
概述
用户在使用 DLC 原生表(Iceberg)时,可以参考如下流程进行原生表创建和完成相关的配置。

步骤一:开启托管存储
说明:
托管存储需要 DLC 管理员开启。
步骤二:创建 DLC 原生表
创建原生表有两种方式。
1. 通过控制台界面可视化建表。
2. 通过 SQL 建表。
说明:
创建 DLC 原生表之前,需要先创建数据库。
通过控制台界面建表
通过 SQL 建表
SQL 建表时用户自己编写 CREATE TABLE SQL 语句进行创建,DLC 原生表(Iceberg)创建不需要指定表描述,不需要指定 location,不需要指定表格式。但根据使用场景,需要自行补充一些高级参数,参数通过 TBLPROPERTIES 的方式带入。
如果您在创建表的时候没有参数,或者要修改某些属性值,可通过 alter table set tblproperties 的方式进行修改,执行 alter table 修改之后,重启上游的导入任务即可完成属性值修改或者增加。
以下提供 Append 场景和 Upsert 场景的典型建表语句,用户在使用时可在该语句的基础上结合实际情况进行调整。
Append 场景建表
CREATE TABLE IF NOT EXISTS `DataLakeCatalog`.`axitest`.`append_case` (`id` int, `name` string, `pt` string)PARTITIONED BY (`pt`)TBLPROPERTIES ('format-version' = '1','write.upsert.enabled' = 'false','write.distribution-mode' = 'hash','write.metadata.delete-after-commit.enabled' = 'true','write.metadata.previous-versions-max' = '100','write.metadata.metrics.default' = 'full','smart-optimizer.inherit' = 'default');
Upsert 场景建表
Upsert 场景建表需要指定 version为2,设置 write.upsert.enabled 属性为 true,且要根据 upsert 的键值设置 bloom,如果用户有多个主键,一般取前两个键值设置 bloom。如果 upsert 表为非分区场景,且 upsert 更新频繁,数据量大,可根据主键做一定的分桶打散。
非分区表及分区表样例参考如下。
// 分区表CREATE TABLE IF NOT EXISTS `DataLakeCatalog`.`axitest`.`upsert_case` (`id` int, `name` string, `pt` string)PARTITIONED BY (bucket(4, `id`))TBLPROPERTIES ('format-version' = '2','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.parquet.bloom-filter-enabled.column.id' = 'true','dlc.ao.data.govern.sorted.keys' = 'id','write.distribution-mode' = 'hash','write.metadata.delete-after-commit.enabled' = 'true','write.metadata.previous-versions-max' = '100','write.metadata.metrics.default' = 'full','smart-optimizer.inherit' = 'default');
// 非分区表CREATE TABLE IF NOT EXISTS `DataLakeCatalog`.`axitest`.`upsert_case` (`id` int, `name` string, `pt` string)TBLPROPERTIES ('format-version' = '2','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.parquet.bloom-filter-enabled.column.id' = 'true','dlc.ao.data.govern.sorted.keys' = 'id','write.distribution-mode' = 'hash','write.metadata.delete-after-commit.enabled' = 'true','write.metadata.previous-versions-max' = '100','write.metadata.metrics.default' = 'full','smart-optimizer.inherit' = 'default');
修改表属性
如果用户在创建表的时候没有携带相关属性值,可通过 alter table 将相关属性值进行修改、添加和移除,如下所示。如涉及到表属性值的变更都可以通过改方式。特别的 Iceberg format-version 字段不能修改,另外如果用户表已经有 inlong/oceans/flink 实时导入,修改后需要重启上游导入业务。
// 修改冲突重试次数为10ALTER TABLE `DataLakeCatalog`.`axitest`.`upsert_case` SET TBLPROPERTIES('commit.retry.num-retries' = '10');
// 取消name字段bloom设置ALTER TABLE `DataLakeCatalog`.`axitest`.`upsert_case` UNSET TBLPROPERTIES('write.parquet.bloom-filter-enabled.column.id');
步骤三:数据优化与生命周期配置
数据优化与生命周期配置有两种方式。
1. 通过控制台界面可视化配置。
2. 通过 SQL 进行配置。
通过控制台界面配置
通过 SQL 配置
配置数据库
数据库的数据优化和生命周期可通过变更 DBPROPERTIES 进行,如下所示。
// 针对my_database表开启写入优化,且不继承数据目录策略ALTER DATABASE DataLakeCatalog.my_database SET DBPROPERTIES ('smart-optimizer.inherit'='none', 'smart-optimizer.written.enable'='enable');
// 设置my_database继承数据目录策略ALTER DATABASE DataLakeCatalog.my_database SET DBPROPERTIES ('smart-optimizer.inherit'='default');
// 针对my_database表关闭生命周期,且不继承数据目录策略ALTER DATABASE DataLakeCatalog.my_database SET DBPROPERTIES ('smart-optimizer.inherit'='none', 'smart-optimizer.lifecycle.enable'='disable');
配置数据表
数据表的数据优化和生命周期通过变更 TBLPROPERTIES 进行,如下所示。
// 针对upsert_cast表关闭写入优化,且不继承数据库策略ALTER TABLE `DataLakeCatalog`.`axitest`.`upsert_case` SET TBLPROPERTIES('smart-optimizer.inherit'='none', 'smart-optimizer.written.enable'='disable');
// 设置upsert_cast表继承数据库策略ALTER TABLE `DataLakeCatalog`.`axitest`.`upsert_case` SET TBLPROPERTIES('smart-optimizer.inherit'='default');
// 针对upsert_cast表开启生命周期并设置生命周期时间为7天,且不继承数据库策略ALTER TABLE `DataLakeCatalog`.`axitest`.`upsert_case` SET TBLPROPERTIES('smart-optimizer.inherit'='none', 'smart-optimizer.lifecycle.enable'='enable', 'smart-optimizer.lifecycle.expiration'='7');
步骤四:数据入湖到原生表
步骤五:查看数据优化任务
您可以在 DLC 控制台数据运维菜单,进入历史任务页面查看数据治理任务。可以"CALL"、"Auto"、库名称和表名称等关键字查询任务。
说明:
查看系统数据优化任务的用户需要具备 DLC 管理员权限。
任务 ID 为 Auto 开头的任务都是自动产生的数据优化任务。如下图所示。
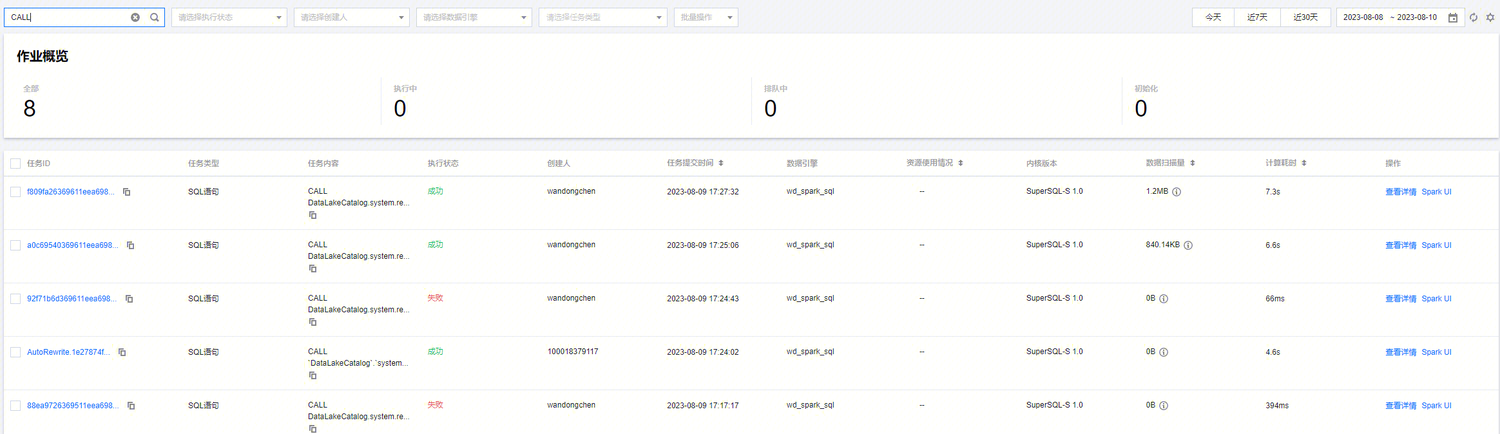
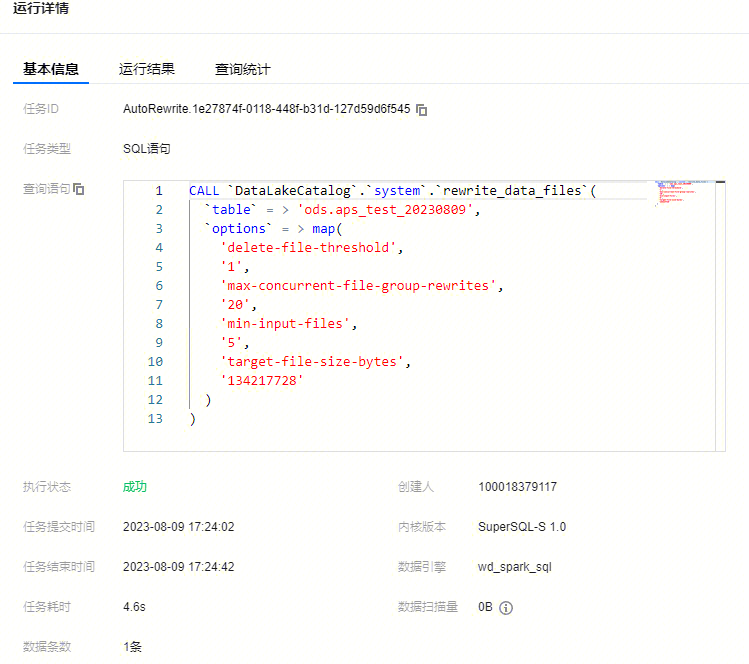
您也可以点击查看详情,查询任务的基本信息和运行结果。
文档反馈