DLC + Wedata 分布式离线推理实践教程
Download
聚焦模式
字号
本文以鸢尾花数据集为例,通过 DLC 与 WeData 联动,依托 SparkMLlib 框架实现分布式离线推理。
说明:
背景介绍
数据湖计算 DLC 支持使用机器学习资源组中的 SparkMLlib 框架进行分布式离线推理,协助用户实现大规模数据(TB/PB级)情景下的模型训练。
离线推理(Batch Inference):是指模型一次性对按照批划分的静态数据进行批量预测的计算过程。
分布式离线推理:是离线推理的一种实现方式,通过分布式计算框架(如 Spark)将批量预测任务分配到多台机器上并行执行。
准备工作
1. 开通账号与产品:通过主账号开通 DLC 账号,WeData 账号以及相关功能。
2. 配置数据访问策略:用户在访问管理(CAM)上对数据访问权限进行策略配置。
前往 DLC 配置资源,准备数据集
步骤一:购买计算资源,创建资源组
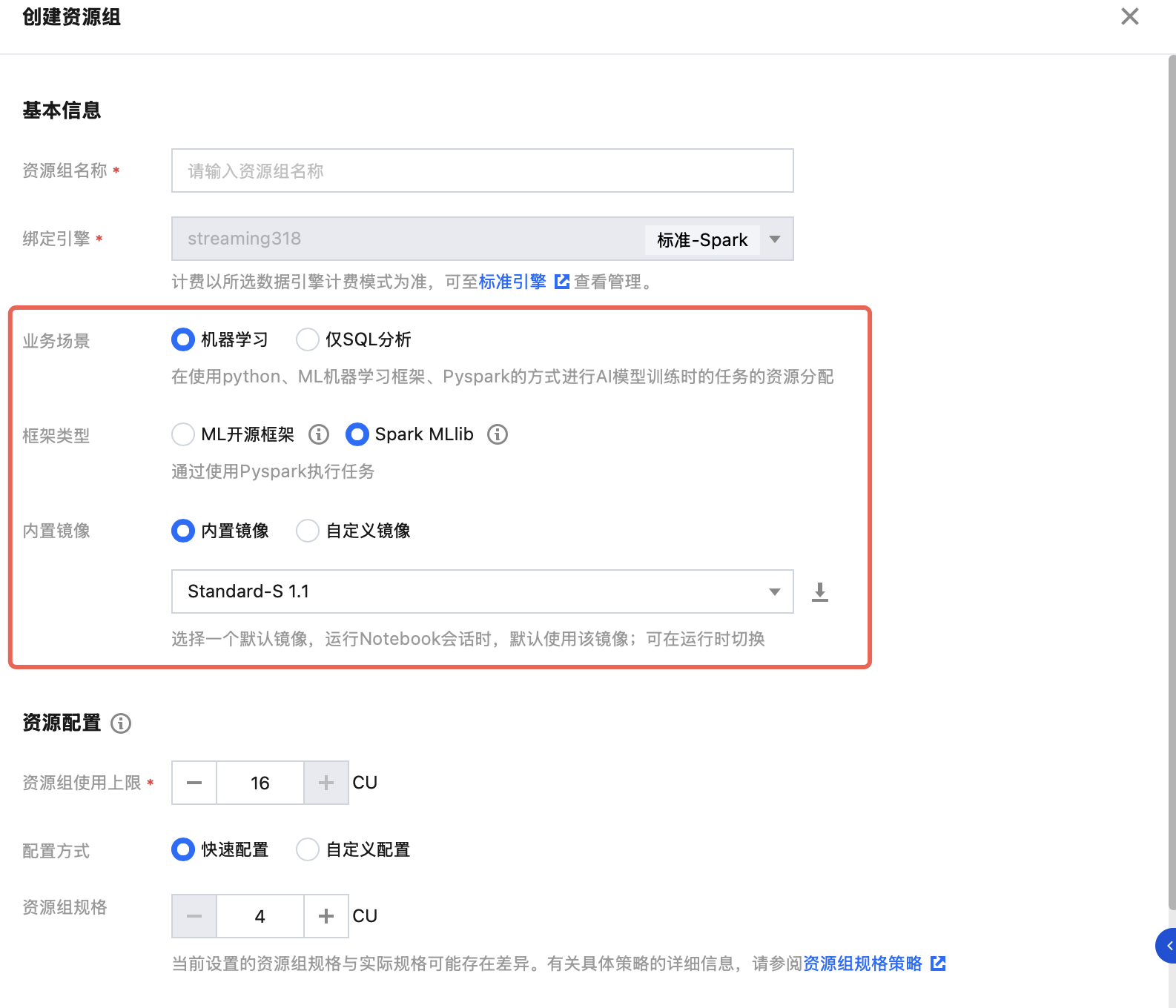
准备工作完成后,通过数据湖计算 DLC 购买计算资源,并创建以机器学习为业务场景、依托 SparkMLlib 的资源组。
1. 购买计算资源:
2. 创建资源组:
返回 标准引擎 页面,您需要在该引擎下,创建以机器学习为业务场景、依托 SparkMLlib 框架的资源组,实现分布式离线推理。创建资源组步骤请参见 创建机器学习资源组,注意业务场景选择机器学习,框架类型选择Spark MLlib,内置镜像选择Standard-S1.1。
步骤二:上传 COS 中的数据集至 DLC
前往 WeData 进行离线推理
资源组与数据集创建完成后,前往 WeData 通过 Notebook 和 MLflow 进行离线推理。
步骤一:创建 WeData 项目并关联 DLC 引擎
1. 创建项目或选择已有的项目,详情请参见 项目列表。
2. 在配置存算引擎中选择所需的 DLC 引擎。
步骤二:购买执行资源组并关联项目
步骤三:运行离线推理 Notebook 文件
1. 创建 Notebook 工作空间:
在项目中选择数据治理功能,单击 Notebook 功能,进入Notebook探索页面,单击创建工作空间。
创建工作空间页面,请选择购买标准 Spark 引擎,standard-S 1.1版本的引擎,勾选机器学习选项以及 MLflow 服务。该页面的配置操作详情请参见 创建 Notebook 工作空间。
2. 创建 Notebook 文件:在左侧资源管理器可以创建文件夹和 Notebook 文件,注意:Notebook 文件需要以(.ipynb)结尾。在资源管理器中,预先内置了两个大数据系列教程,支持用户开箱即用。
3. 选择内核(kernel):
单击选择内核。

在下拉选项中选择“DLC资源组”。
在下一级选项中选择 DLC 数据引擎中的您创建的 Spark MLlib 资源组。
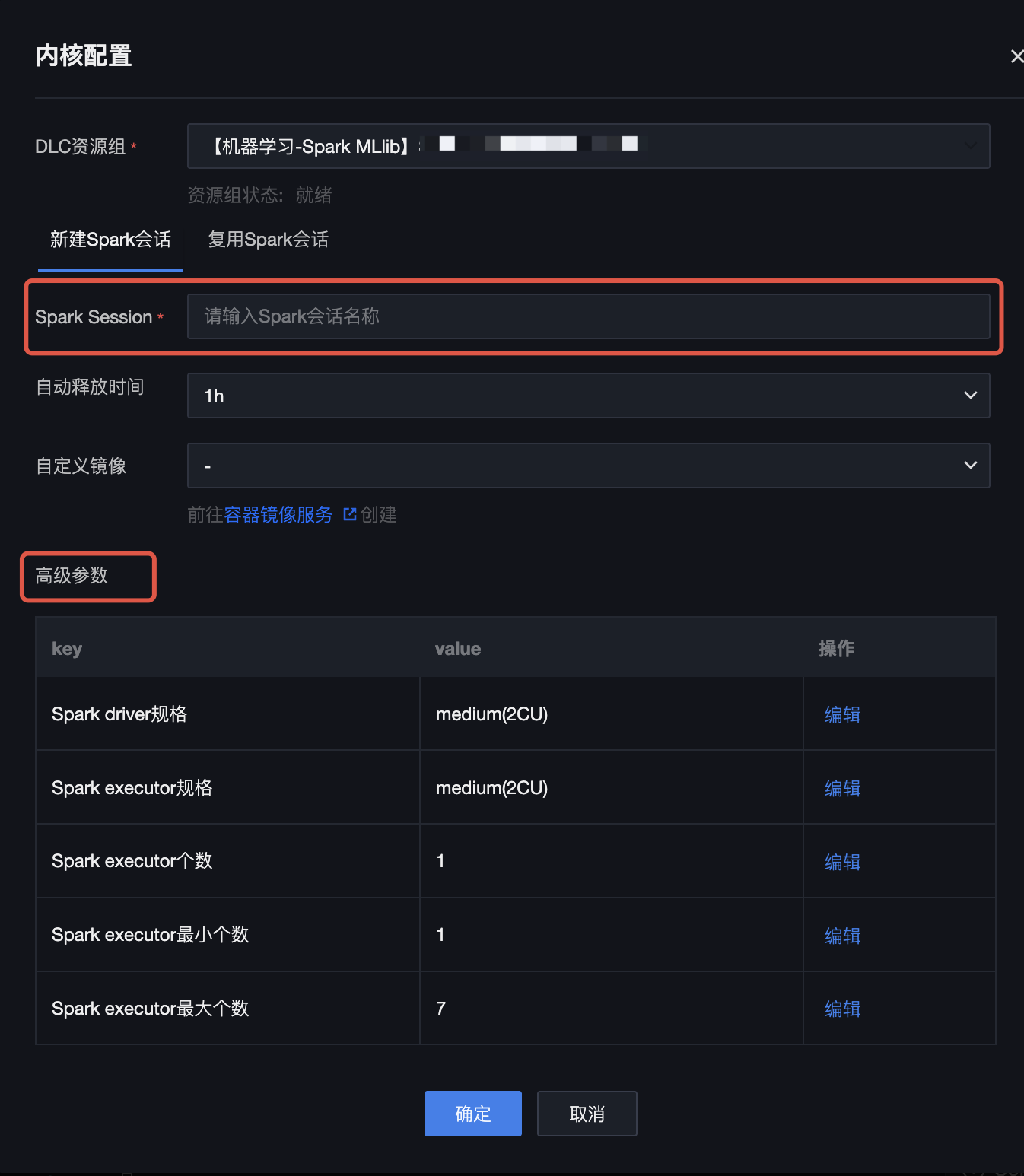
4. 单击运行按钮,弹出内核配置窗口,自定义 Spark 会话名称(此处命名为test2),用于在 DLC 中查找该会话,可设置自动释放时间,通过编辑高级参数协调计算资源。
执行实践教程:通过两种方式加载数据集,采用K近邻算法对不同类型的花分类并输出分类结果。
from pyspark.sql import SparkSessionfrom sklearn import datasetsfrom sklearn.neighbors import KNeighborsClassifierimport mlflowfrom mlflow.models import infer_signaturespark = SparkSession.builder.getOrCreate()#加载数据集#方法一:通过机器学习库加载数据集X, y = datasets.load_iris(as_frame=True, return_X_y=True)#方法二:通过tencentcloud-dlc-connector加载DLC中数据#安装驱动!pip install tencentcloud-dlc-connector!pip install --upgrade 'sqlalchemy<2.0'#安装版本!pip install --upgrade pandas==2.2.3!pip install numpy!pip install matplotlibimport pandas as pdimport numpy as npimport tdlc_connectorfrom tdlc_connector import constantsmlflow.sklearn.autolog()#使用 tdlc-connector 按照表方式访问conn = tdlc_connector.connect(region="ap-***", #填入正确地址,如ap-Singapore,ap-Shanghaisecret_id="*******",secret_key="*******",engine="your engine",#填入购买的引擎名称resource_group=None,engine_type=constants.EngineType.AUTO,result_style=constants.ResultStyles.LIST,download=True)query = """SELECT `sepal.length`, `sepal.width`,`petal.length`,`petal.width`,species FROM at_database_testnotebook.demo_test_sklearn"""iris = pd.read_sql(query, conn)spark_iris = spark.createDataFrame(iris)#划分特征列与目标列feature_cols = ["sepal_length", "sepal_width", "petal_length", "petal_width"]X = spark_iris.select(feature_cols)X = spark_iris.select(feature_cols)y = spark_iris.select("species")#使用K近邻算法进行分类model = KNeighborsClassifier()model.fit(X, y)predictions = model.predict(X)signature = infer_signature(X, predictions)with mlflow.start_run():model_info = mlflow.sklearn.log_model(model, artifact_path="model", signature=signature)infer_spark_df = spark.createDataFrame(X)pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_info.model_uri)result = infer_spark_df.select(pyfunc_udf(*X.columns).alias("predictions")).toPandas()print(result)
步骤四:查看运行结果与模型管理
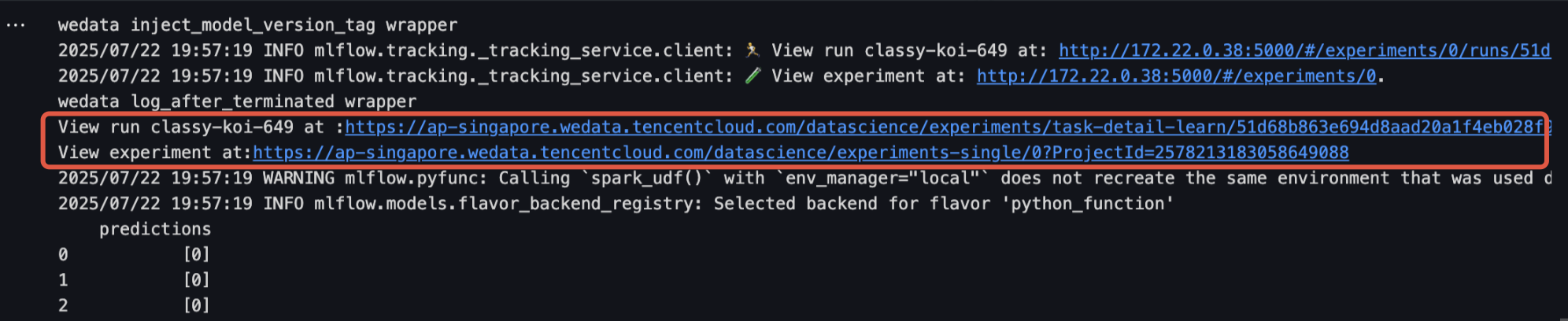
1. 通过单击运行结果中的链接进入模型实验界面,该界面显示了模型的详细信息,单击模型注册即可将该模型保存至模型管理。
2. 模型管理界面可查看注册的模型以及模型版本。
前往 DLC 查看 Spark 会话
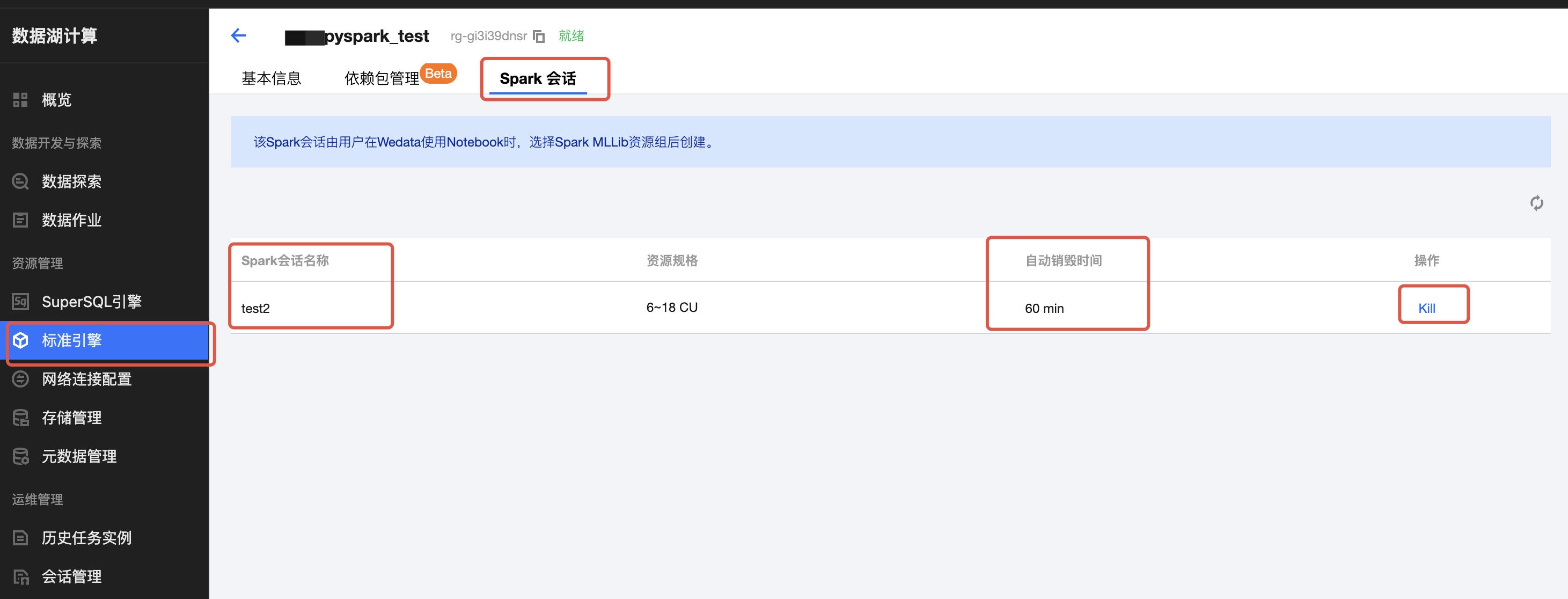
1. 返回 标准引擎 页面,进入您购买的引擎的详情页,选择资源组管理。
2. 单击创建的资源组(依托 SparkMLlib 框架),选择Spark会话,查看 Spark 会话的自动销毁时间,可以通过操作栏下的 Kill 销毁 Spark 会话。
文档反馈