引擎本地缓存
Download
聚焦模式
字号
为保证在网络带宽受限的情况下(例如触发存储系统的限流),Spark 引擎查询分析能稳定运行,DLC Spark 引擎提供本地缓存(Local Cache)能力。当您需要缓存表数据时,可以通过添加引擎配置快速开启缓存功能。
操作步骤
1. 创建 Spark 引擎,详情请参见 购买独享数据引擎。
2. 添加缓存配置,进入 DLC 控制台 > 数据引擎,选择步骤1创建的引擎,单击参数配置,将 缓存配置项说明 中的配置项添加到引擎配置中。
Spark SQL 引擎配置:
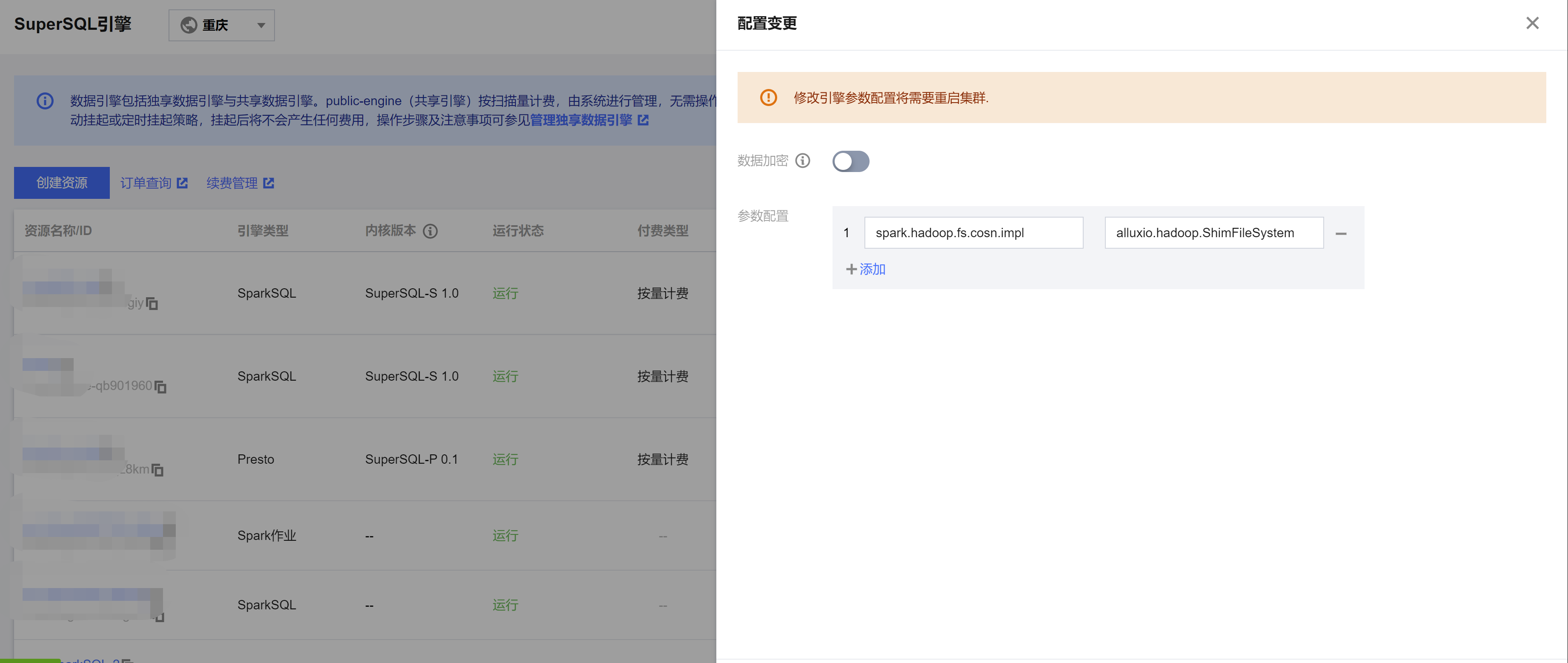
说明:
添加配置后,引擎集群会重启,建议在没有跑任务的情况下开启缓存,避免影响正在运行的任务。
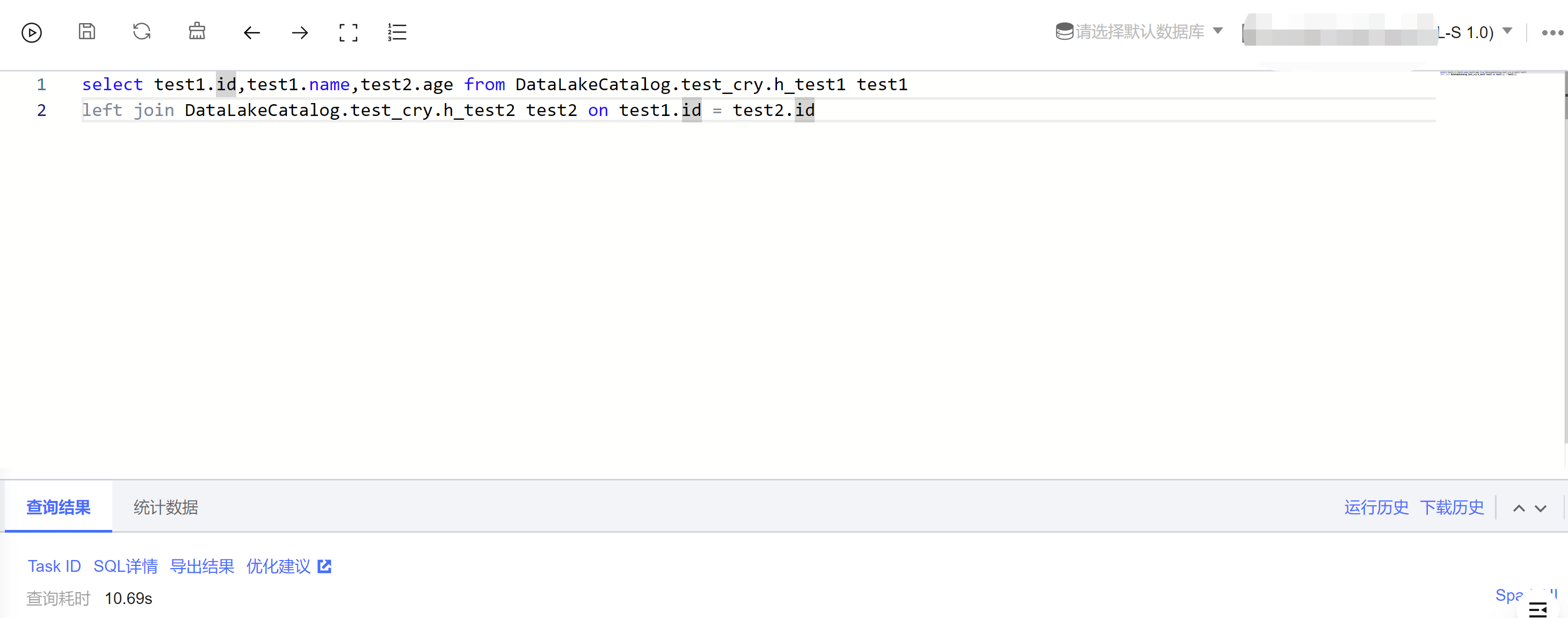
3. 使用引擎缓存,进入 数据探索,SQL 界面编写查询 SQL,选择开启缓存的引擎,执行 SQL,执行完毕。引擎会将 SQL 中涉及的 DLC 外表缓存到本地,当再次执行 SQL 时,数据会从本地缓存获取,提升查询效率。
Spark SQL 引擎查询:
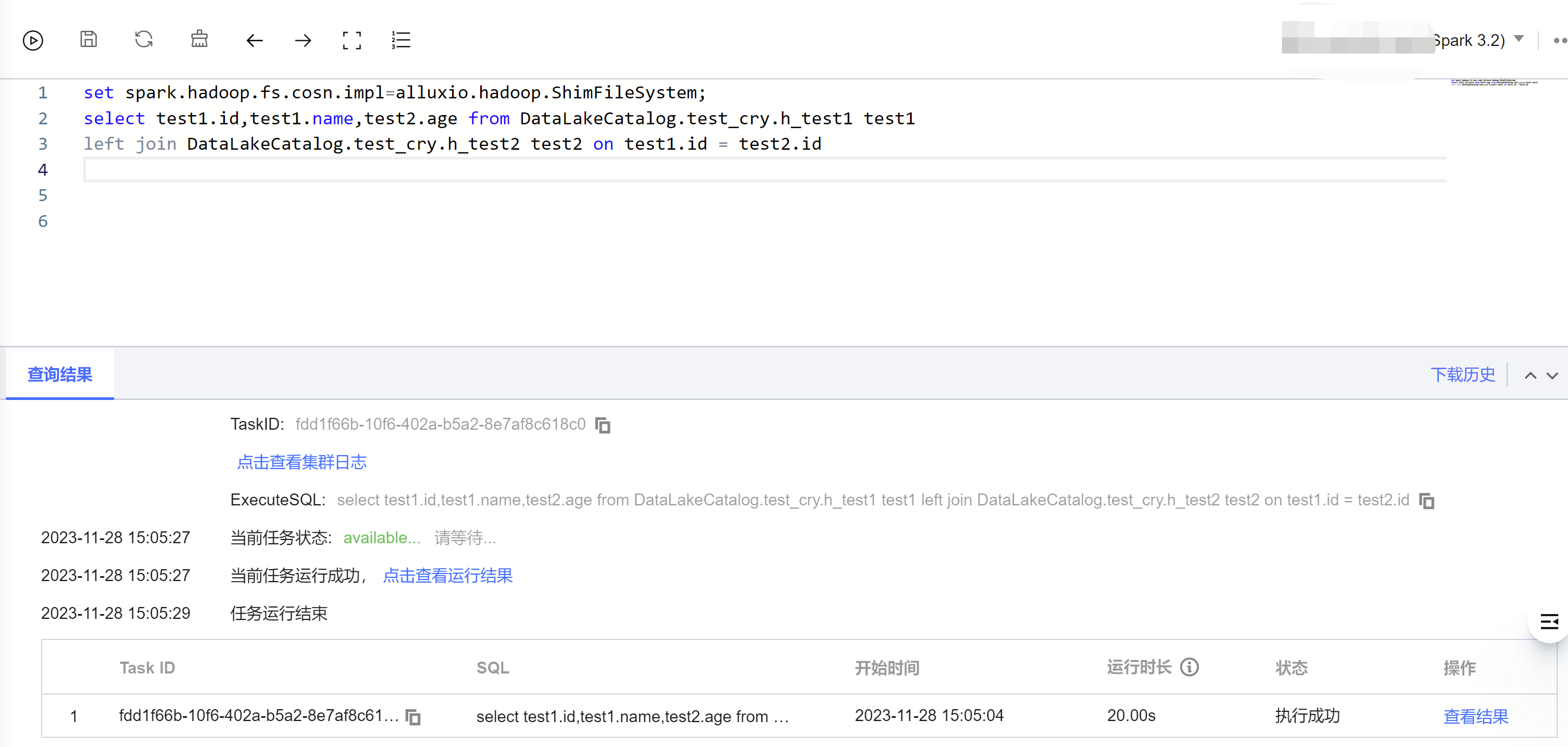
Spark Batch 引擎查询:
缓存说明
缓存配置项说明
配置项 | 配置值 | 配置项说明 |
spark.hadoop.fs.cosn.impl | alluxio.hadoop.ShimFileSystem | 固定值;配置值为缓存功能实现类。配置该值为开启缓存功能;开启缓存功能时,若配置非该值的其他值,会导致引擎访问不到 COS 数据,请谨遵指引配置。 若开启缓存后需关闭缓存,请删除该配置项。 |
缓存使用说明
1. 引擎类型说明
SparkSQL 引擎:当引擎重新启动后,因缓存为本地缓存,故原缓存的数据会失效。
SparkBatch 引擎:SparkBatch 引擎运行任务为 Session 级别,任务执行完,缓存数据失效。
2. 表类型说明
目前只缓存 DLC 外表。
文档反馈