大規模モデルによるビデオ要約の導入
Download
フォーカスモード
フォントサイズ
無料で体験
説明:
体験ラボの機能は限定的であり、基本的な効果を体験するためのものです。完全な機能をテストするには、API経由で導入してください。
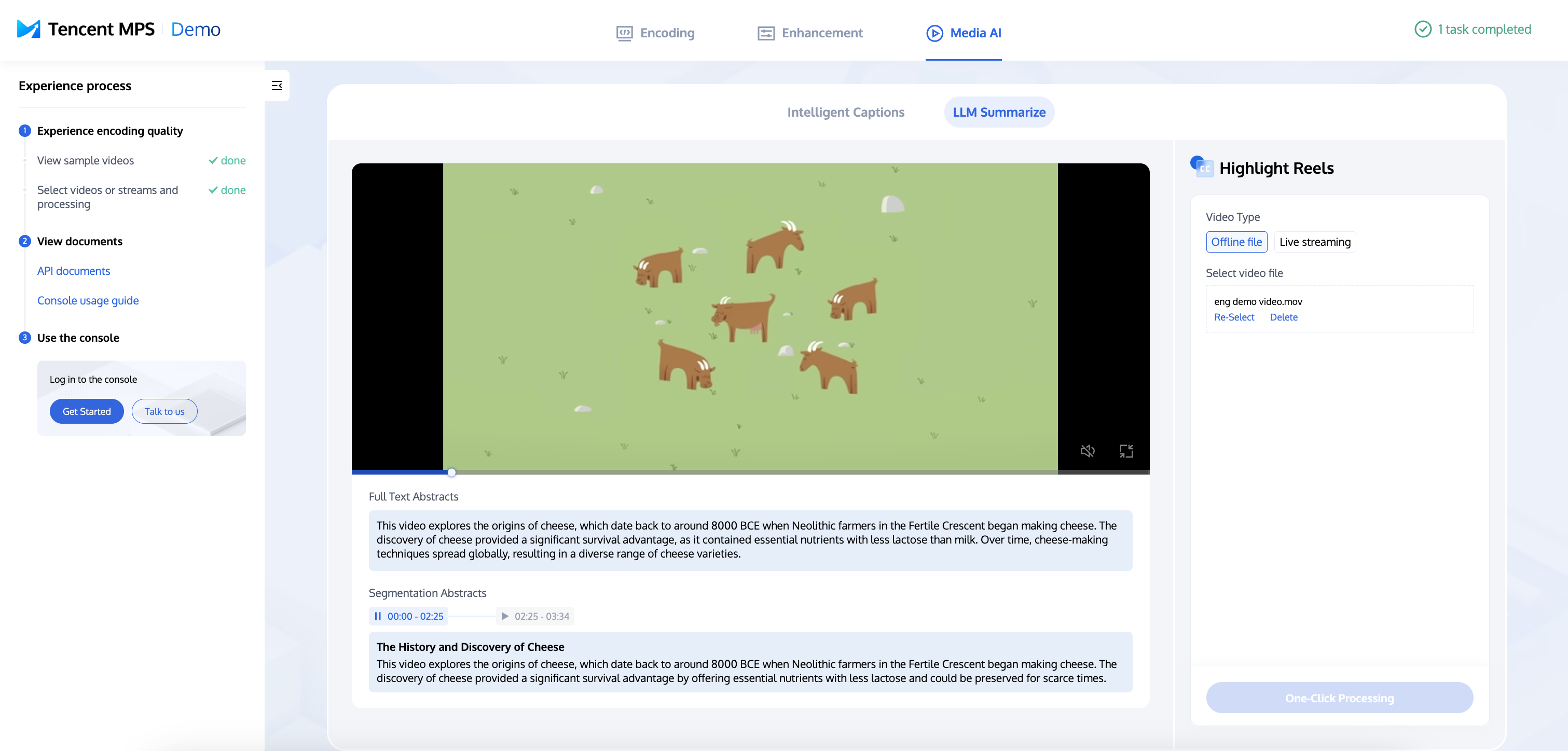
1. 体験ラボを開き、「LLM Summarize」の体験ページに移動します。オフラインビデオ(Offline File)またはライブストリーム(Live Streaming)を選択し、処理を開始(One-Click Processing)をクリックします。
2. 処理が完了すると、結果を確認できます。
APIによる導入
要約タスクの開始
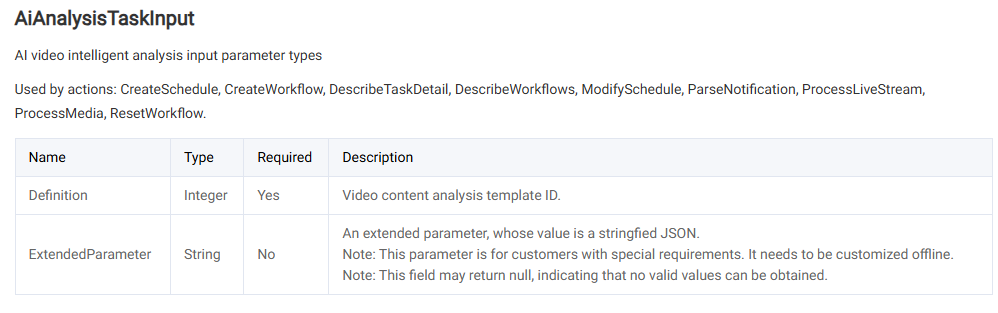
メディア処理APIを呼び出し、AiAnalysisTask タスクを選択し、Definitionを22(プリセットの大規模モデルによる動画要約テンプレート)に設定します。ExtendedParameterには追加の拡張パラメータを記入し、特定の機能を実現します。設定値の詳細は、下記の拡張パラメータの説明をご参照ください。
例:
{"InputInfo": {"Type": "URL","UrlInputInfo": {"Url": "https://facedetectioncos-1251132611.cos.ap-guangzhou.myqcloud.com/video/xxx.mp4" // 要約したいビデオのURLに置き換えてください}},"AiAnalysisTask": {"Definition": 22, // プリセットの大規模モデルビデオ要約テンプレートID"ExtendedParameter": "{\\"des\\":{\\"split\\":{\\"method\\":\\"llm\\",\\"model\\":\\"deepseek-v3\\"}}}"},"OutputStorage": {"CosOutputStorage": {"Bucket": "test-mps-123456789","Region": "ap-guangzhou"},"Type": "COS"},"OutputDir": "/output/","TaskNotifyConfig": {"NotifyType": "URL","NotifyUrl": "http://qq.com/callback/qtatest/?token=xxxxxx"},"Action": "ProcessMedia","Version": "2019-06-12"}
API Explorerによるクイック検証
拡張パラメータの説明
ExtendedParameterは、要約タスクを個別設定するために使用します。最初は入力せず、デフォルトの効果を確認した上で、改善したい方向性に応じて必要に応じて使用してください。
注意:
API Explorerは自動的に変換を行うため、ExtendedParameterには対応するJSONを直接入力してください(文字列への変換は不要です)。APIを直接呼び出す場合は、JSON文字列をエスケープする必要があります。
ExtendedParameterで選択可能なすべてのパラメータとその説明は、以下の表をご参照ください。
{"des": {"split": {"method": "llm","model": "deepseek-v3","max_split_time_sec": 100,"extend_prompt": "このビデオは医療シナリオのビデオです。医療関連の知識ポイントに基づいてビデオをセグメント化してください"},"need_ocr": true,"ocr_type": "ppt","only_segment": 0,"text_requirement": "要約は40字以内""dstlang": "zh"}}
パラメータ | 必須入力かどうか | タイプ | 説明 |
split.method | No | string | ビデオのセグメント化方法。llmは大規模モデルによるセグメント化、nlpは従来のNLPによるセグメント化を指します。デフォルトはllmです。 |
split.model | No | string | セグメント化に使用する大規模モデル。hunyuan、deepseek-v3、deepseek-r1から選択可能。デフォルトはdeepseek-v3です。 |
split.max_split_time_sec | No | int | セグメントの最大時間を秒単位で強制的に指定します。セグメント化の効果に影響する可能性があるため、必要な場合にのみ使用することを推奨します。デフォルトは3600です。 |
split.extend_prompt | No | string | 大規模モデルによるセグメント化タスクへのプロンプトを追記します。例:「このビデオは教育ビデオです。関連する知識ポイントに基づいてビデオをセグメント化してください」。まずは入力せずにテストし、期待する効果が得られない場合に追加することをお勧めします。 |
need_ocr | No | bool | OCRをセグメント化の補助として使用するかどうか。trueで有効、デフォルトはfalseです。 無効の場合、システムはビデオの音声内容のみを認識してセグメント化を補助します。有効の場合、ビデオ画面上の文字内容も認識してセグメント化を補助します。 |
ocr_type | No | string | OCRの補助タイプ。pptは画面をプレゼンテーションとして扱い、スライドの切り替わりに合わせてセグメント化します。otherはその他を指します。デフォルトはpptです。 |
only_segment | No | int | セグメント化のみを行い、要約を生成しないかどうか。デフォルトは0です。 1:セグメント化のみ行い、要約は生成しません。 0:セグメント化と要約生成の両方を行います。 |
text_requirement | No | string | LLMによる要約タスクへのプロンプトを追記します。例:文字数を制限する「要約は40字以内」。 |
dstlang | No | string | ビデオの言語。ビデオの音声認識および要約結果の言語を指定するために使用します。デフォルトは"zh"です。 "zh":中国語 "en":英語 |
タスク結果の照会
タスクコールバック:ProcessMediaからメディア処理タスクを開始する際、TaskNotifyConfigパラメータでコールバック情報を設定できます。タスク処理が完了すると、設定されたコールバック情報を通じてタスク結果が通知されます。ParseNotificationからイベント通知結果を解析できます。
ProcessMediaが返したTaskIdを使用して、タスク詳細の照会インターフェースを呼び出し、タスクの処理結果を照会します。WorkflowTask > AiAnalysisResultSet > DescriptionTask > Output > DescriptionSet > MediaAiAnalysisDescriptionItemを解析してください。
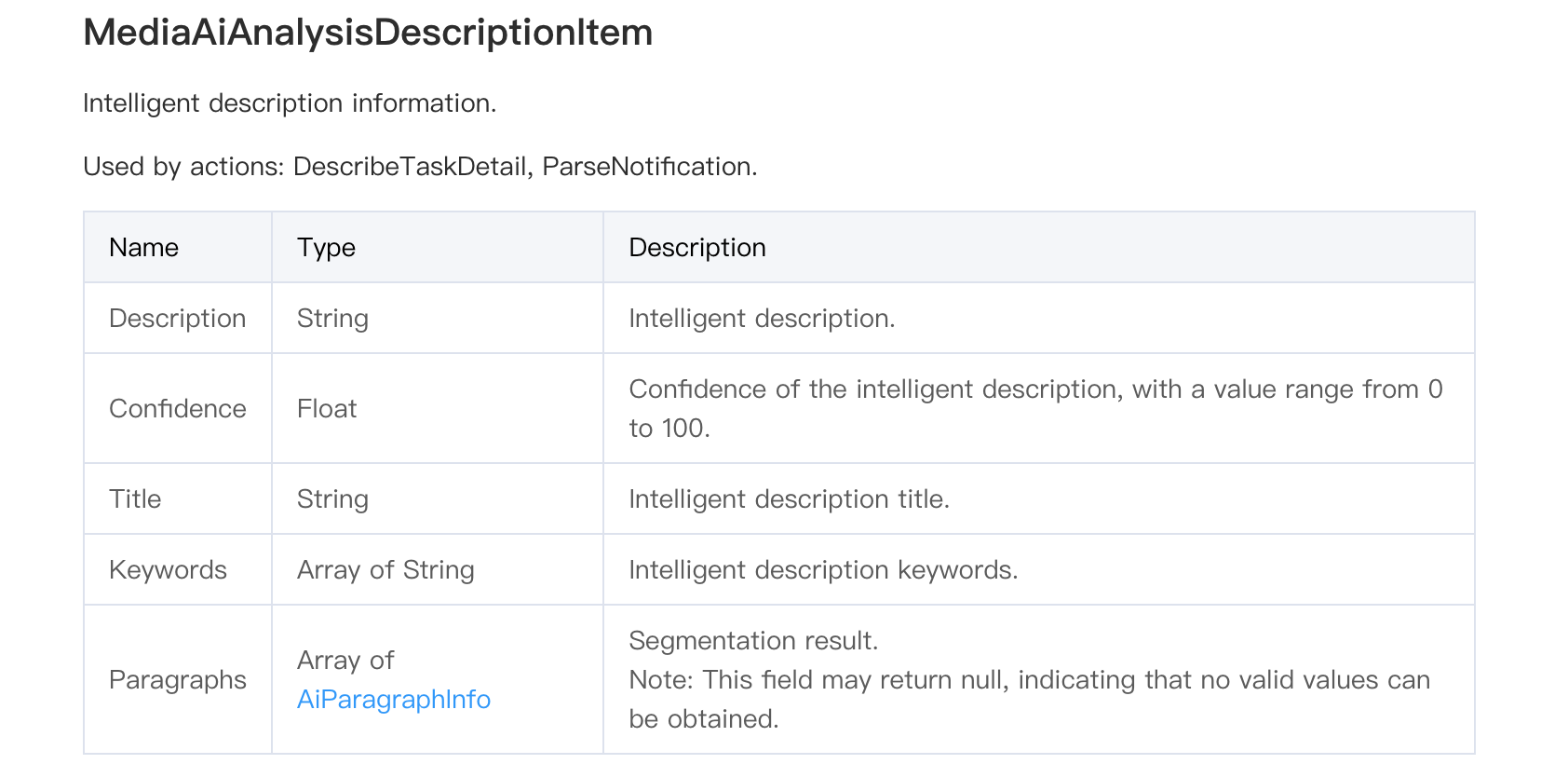
Descriptionはビデオ全体の要約に、Paragraphsはビデオ全体のセグメント化結果および各セグメントの要約に対応します。
フィードバック