AI吹き替えの導入
Download
フォーカスモード
フォントサイズ
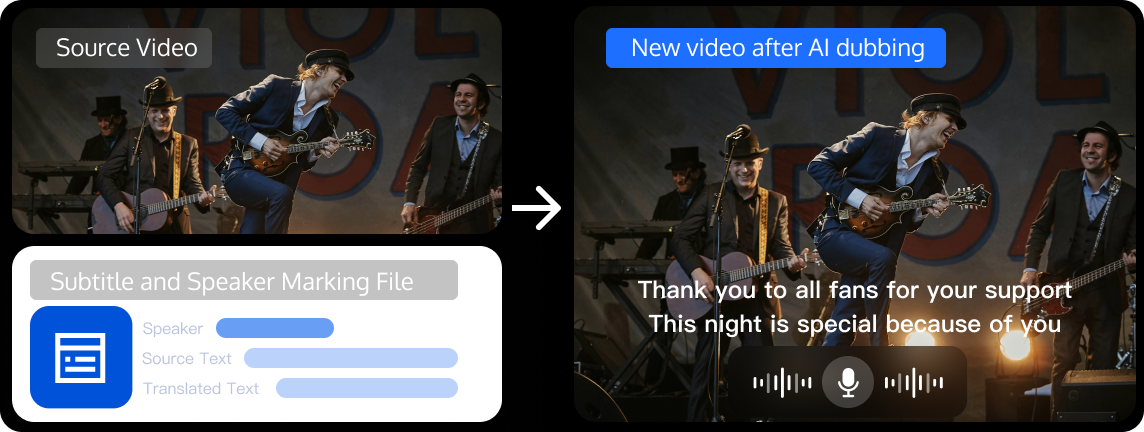
AI吹き替え機能の概要
AI吹き替え機能は、ビデオの元の音声をターゲット言語のAI音声に置き換え、ターゲット言語の字幕を動画画面に焼き込むことができます。AI吹き替えタスクを開始するには、以下の2つのファイルを入力として使用する必要があります。
1. 動画ファイルは字幕のない状態、つまり画面上に元の言語の字幕がないものである必要があります。
2. 字幕および話者マーキングファイル(Speakerファイル)。
説明:
料金説明
AI吹き替えタスクを開始すると、「AI吹き替え(クローン音色)」+「字幕焼き込み」の料金が発生します(字幕焼き込みはオプション)。
説明:
AI吹き替え機能は、デフォルトでクローン音色を使用します。現在、スタンダード音色の機能はアップグレード中のため、暫くクローズドベータテストのみ開放されています。ご利用の場合は、営業担当までお問い合わせください。
スタンダード音色を使用する場合は、「AI吹き替え(クローン音色)」+「字幕焼き込み」の料金が発生します(字幕焼き込みはオプション)。
動画翻訳タスクの開始
導入前の準備
AI吹き替えのご利用前に、MPS製品を正常に利用するためには、以下の準備を完了する必要があります。具体的には、Tencent Cloudアカウントの登録とログイン、MPS製品の有効化とサービスロールへの権限付与です。
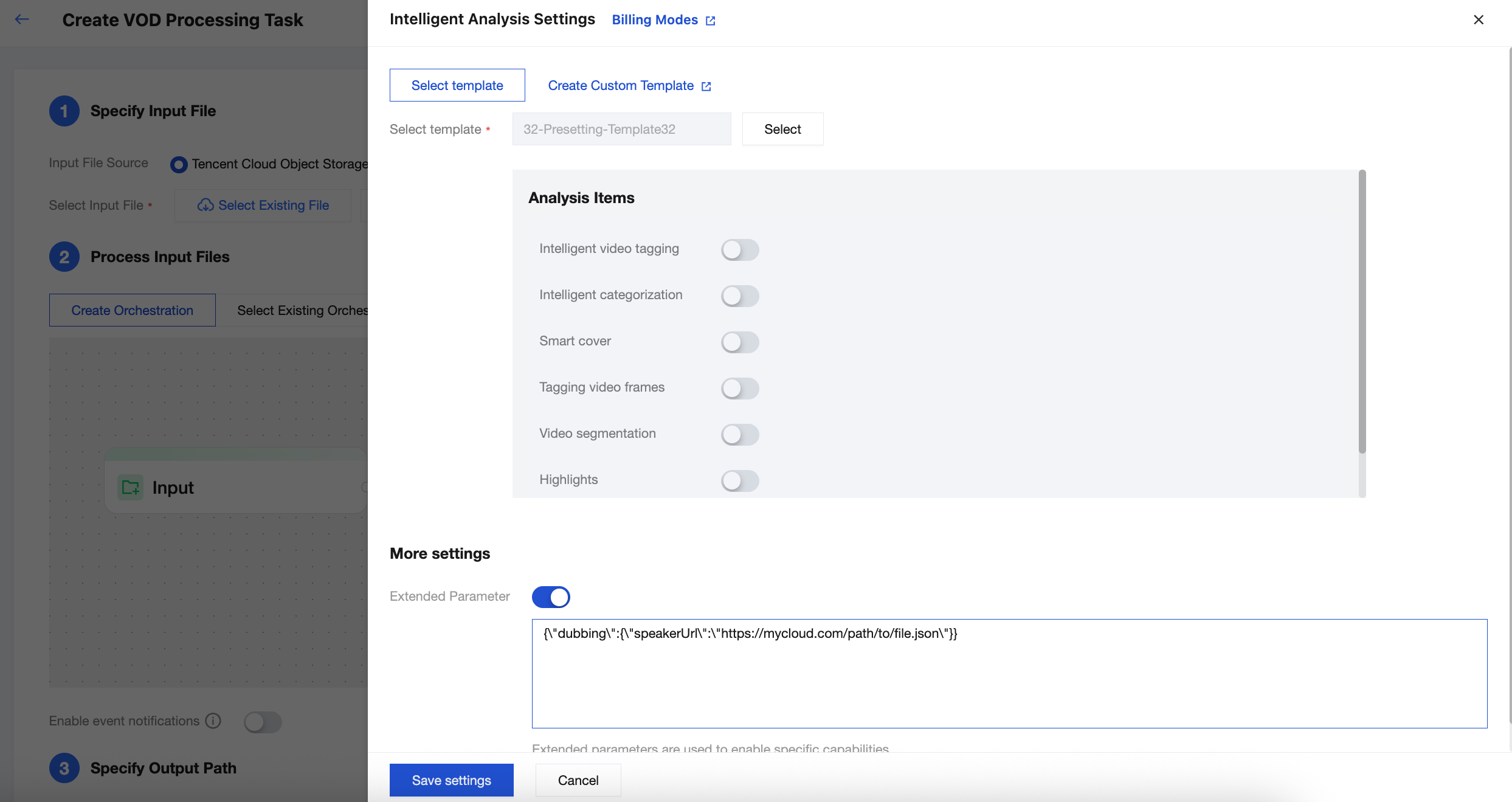
方法1:コンソールからのタスク開始
1. コンソールのタスク作成ページに進み、「入力ファイルパスを選択」→「ワークフローを設定」→「出力パスを指定」を順に行います。
2. ワークフローの設定で、メディアAI - スマート分析ノードを選択します。
3. 右側のポップアップページから32番のプリセットテンプレートを選択します。「詳細設定 - 拡張パラメータ」を開き、以下の拡張パラメータ説明に従って必要なパラメータを入力します。
説明:
AI吹き替えタスクを開始するには、拡張パラメータでSpeakerファイルのパスを必ず入力してください。そうしないとタスクは失敗します。
MPSコンソールは自動的にエスケープ処理を行いますので、JSONデータを直接入力してください。エスケープ後の文字列を渡すと、タスクが失敗します。
方法2:APIによるタスク開始
ProcessMedia APIを呼び出し、AiAnalysisTask タスクを選択し、Definitionを32(プリセットテンプレートID)に設定し、ExtendedParameter に拡張パラメータを入力します。このパラメータによりAI吹き替え機能を実現します。具体的な値は以下の拡張パラメータ説明をご参照ください。ProcessMediaのJSON 例は以下のどおりです。
{"InputInfo":{ //入力ビデオパス。ご自身の元のビデオに置き換えてください"Type":"URL","UrlInputInfo":{"Url":"https://test-1234567.cos.ap-nanjing.myqcloud.com/mps_test/myvideo.mp4"}},"OutputStorage":{ //出力先のCOSバケット。置き換えてください"Type":"COS","CosOutputStorage":{"Bucket":"test","Region":"ap-nanjing"}},"OutputDir":"/mps_test/output/",//出力先のフォルダパス。置き換えてください"AiAnalysisTask":{"Definition":32, //プリセットテンプレートIDで、32とご入力ください"ExtendedParameter":"{\\"dubbing\\":{\\"speakerUrl\\":\\"https://mycloud.com/path/to/file.json\\"}}" //拡張パラメータ。必須。speakerファイルパス、字幕スタイルなどのパラメータ指定に使用},"TaskNotifyConfig":{ //イベントコールバック通知設定。任意"NotifyType":"URL","NotifyUrl":"http://www.qq.com/callback"}}
素早く検証するには、API Explorerの利用をお勧めします。上記のJSONをAPI ExplorerのJSONモードに貼り付け、「フォーム」モードに切り替えると自動解析されます。入力・出力パスなどの必要なパラメータを調整し、呼び出し実行をクリックしてください。
API ExplorerのフォームモードとJSONモードにおける、ExtendedParameterの位置は以下の通りです。
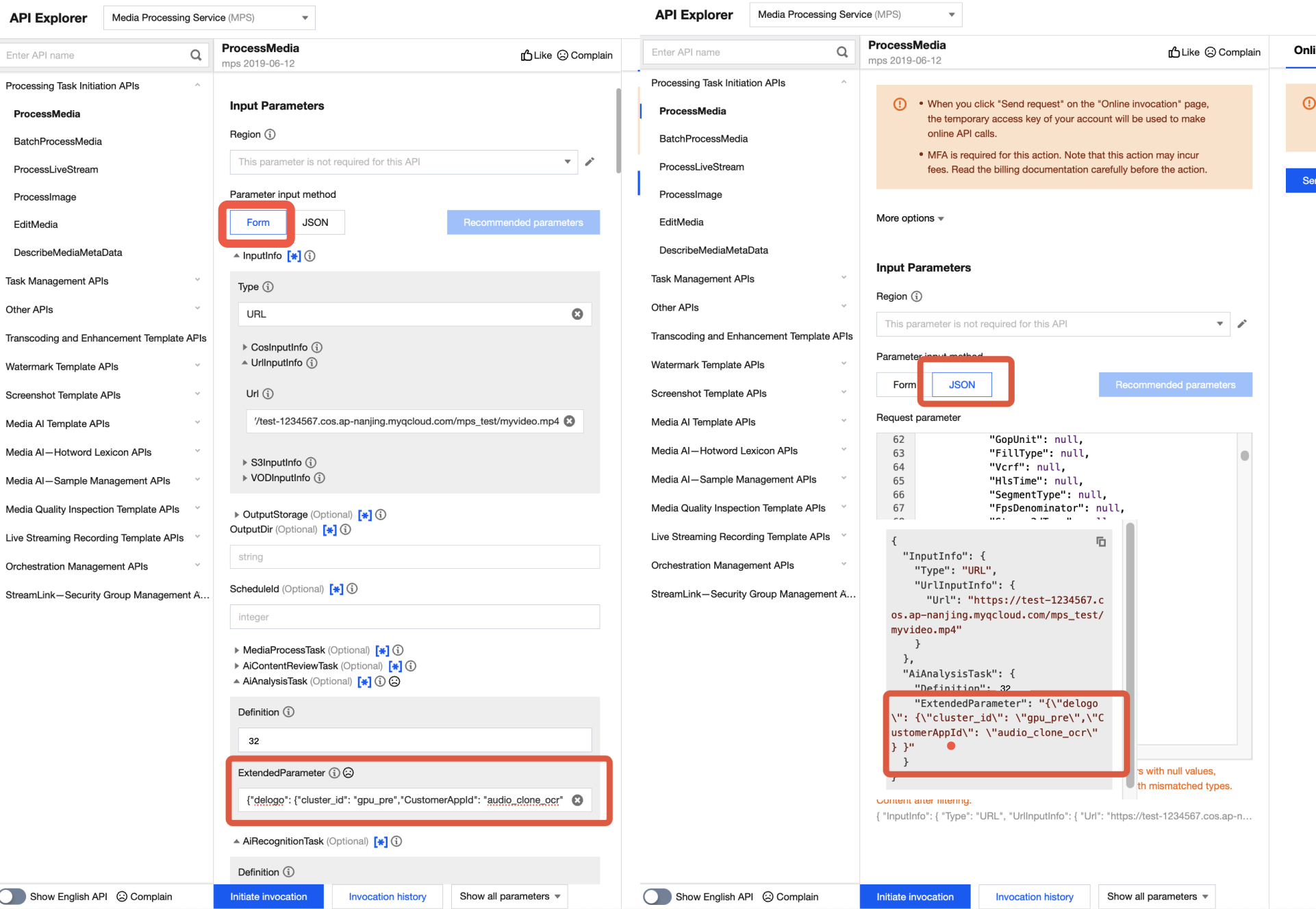
注意:
API ExplorerのフォームモードでExtendedParameterを入力する場合は、JSONを直接入力する必要があり、文字列に変換する必要はありません。ただし、API ExplorerのJSONモードを使用する場合、また直接APIを使用する場合は、エスケープされた文字列を入力する必要があります。
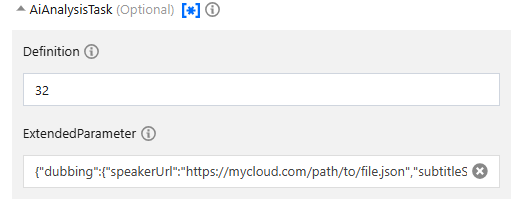
API Explorerのフォームモードでは、ExtendedParameterにJSONを入力するだけで済みます:
API ExplorerのJSONモードでは、ExtendedParameterにエスケープされた文字列を渡す必要があります。例:
{\\"dubbing\\":{\\"speakerUrl\\":\\"https://mycloud.com/path/to/file.json\\"}}
ExtendedParameter拡張パラメータについて
ExtendedParameterは、AI吹き替えタスクの個別設定に使用します。すべての選択可能なパラメータとその説明は以下の通りです。{"dubbing": {"speakerUrl": "https://mycloud.com/path/to/file.json", // 必須、speakerファイルのURL"subtitleStyle": { // 任意。字幕スタイル"embed": true, // 字幕を焼き込むかどうか、デフォルトは有効"style": { // 字幕スタイル、字幕焼き込みが有効な時に適用"font": "simkai", // フォント、デフォルト値"simkai""fontSize": 50, // フォントサイズ、デフォルト値50px"marginV": 50 // 底部までの距離、デフォルト値50}},"outputPattern": "filename" // 任意、出力ファイル名のプレフィックス}}
パラメータ | タイプ | 必須 | 説明 |
speakerUrl | string | はい | SpeakerファイルのURL。 |
subtitle | json | いいえ | 字幕関連パラメータ。 |
subtitle.embed | bool | いいえ | 字幕を焼き込むかどうか。デフォルトは有効。 |
subtitle.style | json | いいえ | 字幕スタイル。字幕焼き込みが有効時に適用されます。 |
subtitle.style.font | string | いいえ | フォント。デフォルト値は "simkai"。 |
subtitle.style.fontSize | float | いいえ | フォントサイズ。デフォルト値は50px。 |
subtitle.style.marginV | float | いいえ | 底部までの距離。デフォルト値は50px。 |
outputPattern | string | いいえ | 出力ファイル名のプレフィックス。指定しない場合のデフォルトプレフィックスはdubで、ファイル名は dub_{unixtime}.{format}となります。 |
Speakerファイル
データ形式
Speakerファイルとは、字幕および対応する話者情報を含むJSON形式のファイルを指します。データ形式は以下の通りです。
{"SrcLang": "zh","DstLangs": ["en"],"Speakers": [{"Id": "speaker_0","Gender": "male"},{"Id": "speaker_1","Gender": "female"}],"Clips": [{"TextStartTime": "00:00:00.100","TextEndTime": "00:00:00.600","SpeakerId": "speaker_0","SrcText": "没谁","DstTexts": {"en": "No one"}},{"TextStartTime": "00:00:01.0","TextEndTime": "00:00:01.200","SpeakerId": "speaker_1","SrcText": "早上好","DstTexts": {"en": "Morning"}}]}
パラメータ | 必須 | タイプ | 説明 |
SrcLang | はい | string | |
DstLangs | はい | list<string> | |
Speakers[i].Id | はい | string | 話者ID。 |
Speakers[i].Gender | はい | string | 話者の性別。maleまたはfemale。 |
Clips[i].TextStartTime | はい | string | 切り抜き動画の字幕の開始タイムスタンプ。時:分:秒.ミリ秒。 |
Clips[i].TextEndTime | はい | string | 切り抜き動画の字幕の終了タイムスタンプ。時:分:秒.ミリ秒。 |
Clips[i].SpeakerId | はい | string | 切り抜き動画の字幕に対応する話者ID。 |
Clips[i].SrcText | はい | string | 切り抜き動画の字幕のソース言語。 |
Clips[i].DstTexts | はい | map<string,string> | 切り抜き動画の字幕のターケット言語。現在は単一の言語のみサポートしています。 |
対応言語
AIによるクローン音色を選択した場合、以下の言語が利用できます。
言語 | Code | ソース言語(SrcLang)として利用可能か | ローカライズのターゲット言語(DstLangs)として利用可能か |
中国語 (Chinese) | zh | ✓ | ✓ |
英語 (English) | en | ✓ | ✓ |
日本語 (Japanese) | ja | ✓ | ✓ |
ドイツ語 (German) | de | ✓ | ✓ |
フランス語 (French) | fr | ✓ | ✓ |
韓国語 (Korean) | ko | ✓ | ✓ |
ロシア語 (Russian) | ru | ✓ | ✓ |
ウクライナ語 (Ukrainian) | uk | ✓ | ✓ |
ポルトガル語 (Portuguese) | pt | ✓ | ✓ |
イタリア語 (Italian) | it | ✓ | ✓ |
スペイン語 (Spanish) | es | ✓ | ✓ |
インドネシア語 (Indonesian) | id | ✓ | ✓ |
オランダ語 (Dutch) | nl | ✓ | ✓ |
トルコ語 (Turkish) | tr | ✓ | ✓ |
フィリピン語 (Filipino) | fil | ✓ | ✓ |
マレー語 (Malay) | ms | ✓ | ✓ |
ギリシャ語 (Greek) | el | ✓ | ✓ |
フィンランド語 (Finnish) | fi | ✓ | ✓ |
クロアチア語 (Croatian) | hr | ✓ | ✓ |
スロバキア語(Slovak) | sk | ✓ | ✓ |
ポーランド語 (Polish) | pl | ✓ | ✓ |
スウェーデン語 (Swedish) | sv | ✓ | ✓ |
ヒンディー語 (Hindi) | hi | ✓ | ✓ |
ブルガリア語 (Bulgarian) | bg | ✓ | ✓ |
ルーマニア語 (Romanian) | ro | ✓ | ✓ |
アラビア語 (Arabic) | ar | ✓ | ✓ |
チェコ語 (Czech) | cs | ✓ | ✓ |
デンマーク語 (Danish) | da | ✓ | ✓ |
タミル語 (Tamil) | ta | ✓ | ✓ |
ハンガリー語 (Hungarian) | hun | ✓ | ✓ |
ベトナム語 (Vietnamese) | vi | ✓ | ✓ |
タスク結果の確認
AI吹き替えタスクは、処理後の動画ファイルと、調整後のSpeakerファイル(吹き替えと同時に、元のSpeakerファイルの訳文を最適化・簡略化し、話速が速くなりすぎないよう正常な速度を保証するため、新しいSpeakerファイルが生成されます)を出力し、タスク設定の出力パスに保存します。
コンソールでの確認
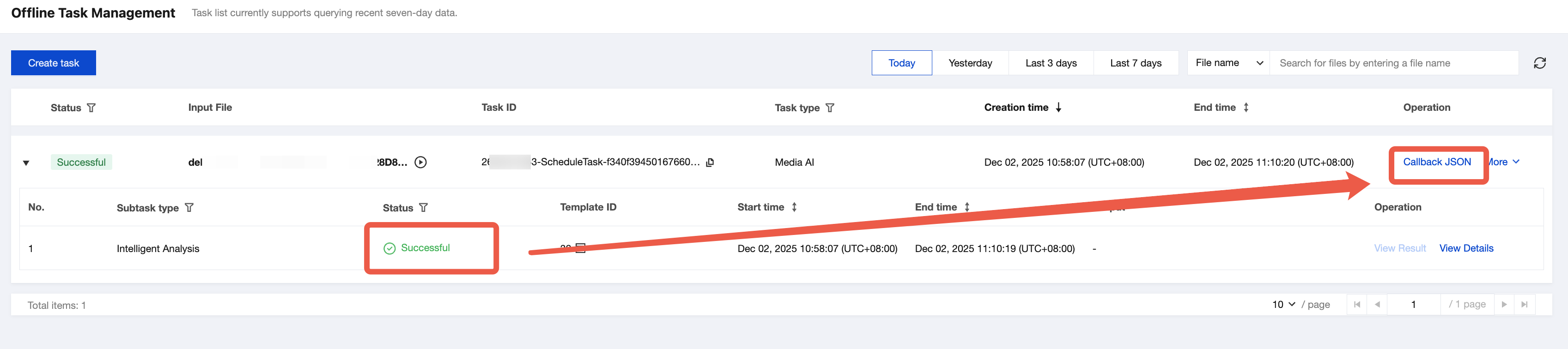
1. コンソールのタスク管理ページでタスクのステータスを確認できます。サブタスクのステータスが「成功」になった場合、コールバックJSONをクリックしてください。
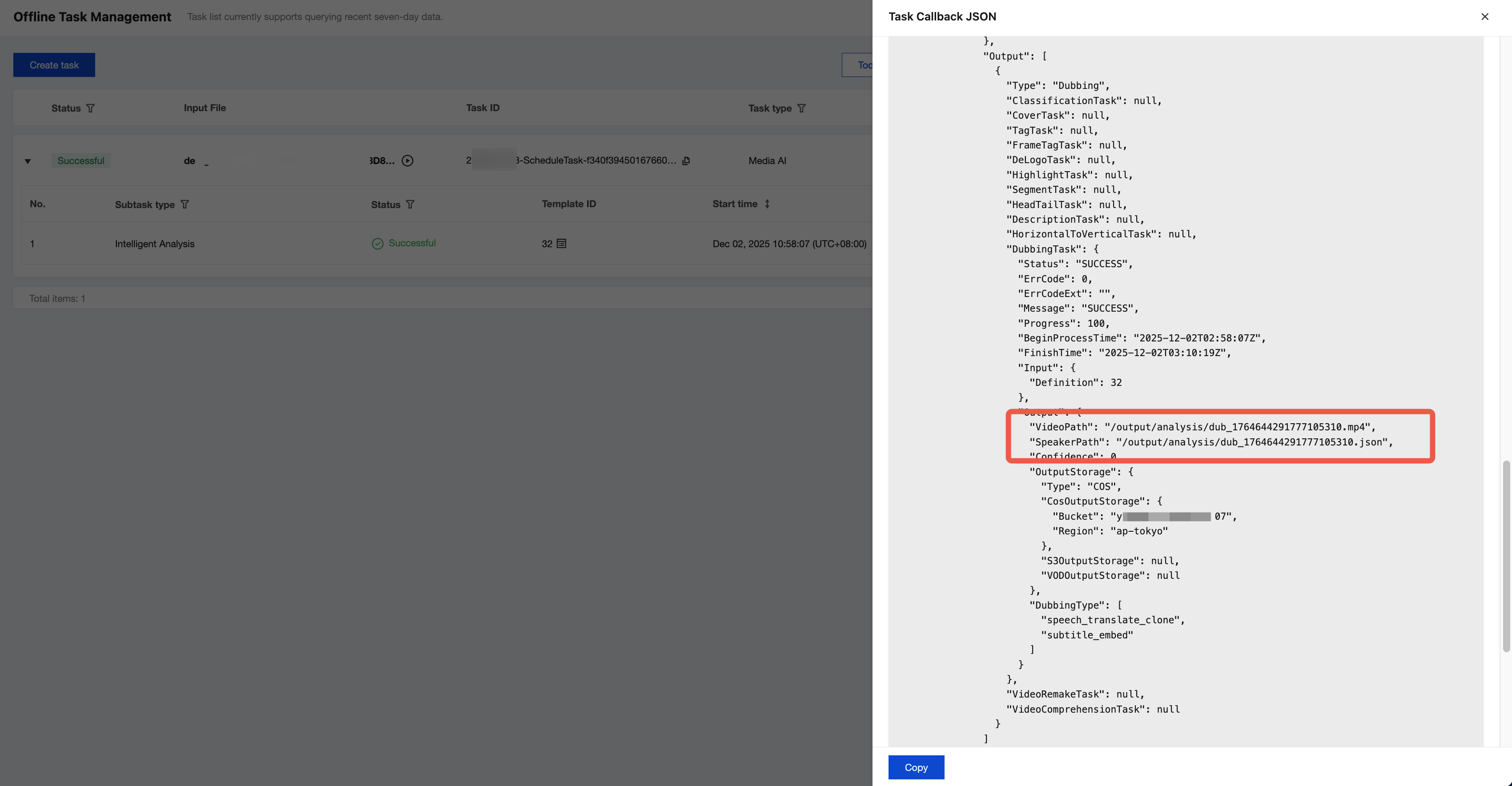
2. 出力情報から出力ファイルのパスを確認できます。
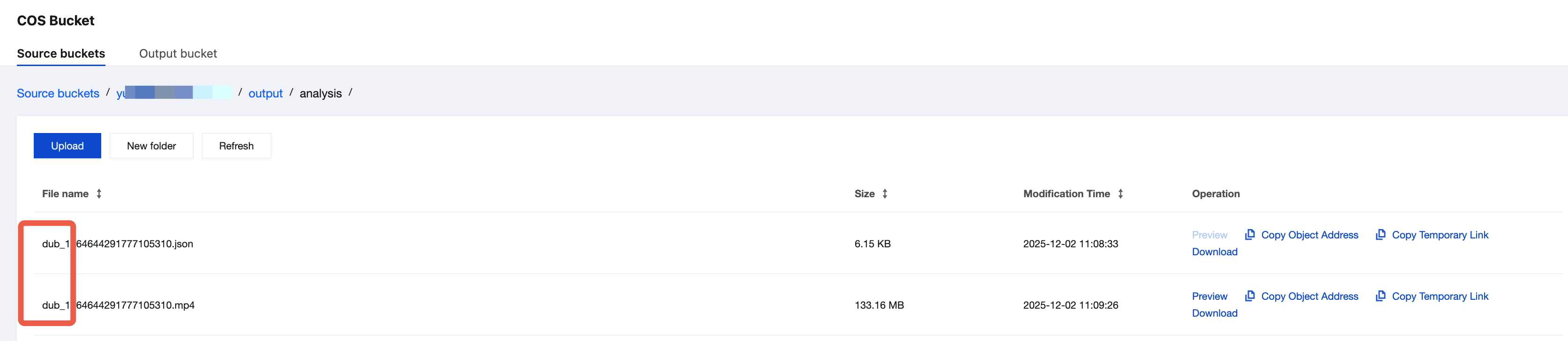
出力先をCOSに設定した場合、出力されたファイルは、MPSコンソールのワークフロー管理 > COS Bucket > 出力Bucket ページで確認できます。「dub-xxx.mp4」、「dub-xxx.json」のようなファイル名のファイルが、AI吹き替え処理済みの動画ファイルおよびSpeakerファイルです。
イベント通知コールバック
ProcessMediaでメディア処理タスクを開始する際、TaskNotifyConfigパラメータでイベントコールバックを設定できます。タスク処理が完了すると、設定されたコールバック情報を通じてタスク結果がコールバックされます。ParseNotificationでイベント通知結果を解析可能です。以下に関連データ構造を参考に示します。
API呼び出しによるタスク結果の照会
ProcessMediaを使用してメディア処理タスクを開始すると、タスクID(TaskId)が返されます。例:24000022-WorkflowTask-b20a8exxxxxxx1tt110253、24000022-ScheduleTask-774f101xxxxxxx1tt110253。DescribeTaskDetailAPIを呼び出し、タスクIDを入力するとタスク結果を取得できます。WorkflowTask->AiAnalysisResultSet>DubbingTask>Outputフィールドを解析してタスク結果を取得する必要があります。以下に関連データ構造を参考に示します。
関連データ構造
よくあるご質問
字幕なし動画を取得するには?
動画を入力し、字幕除去+字幕翻訳+字幕焼き込み+AI吹き替えをワンストップで処理することはできますか?
SRT/VTT形式の字幕ファイルからSpeakerファイルを生成するには?
SRTまたはVTT形式の字幕ファイルをサポートしています。使用例は以下の通りです。
二ヶ国語字幕ファイル(元の字幕と翻訳済みの字幕が同じファイル内にある)を提供する場合:
python3 subtitle2speaker.py input.srt output.json --src_lang "zh" --dst_langs "en"
2つの単一言語字幕ファイル(元の字幕と翻訳済みの字幕が別々のファイルにある)を提供する場合:
python3 subtitle2speaker.py input_src.vtt input_dst.vtt output.json --src_lang "zh" --dst_langs "en"
説明:
SRT/VTT形式の字幕ファイルから生成されたSpeakerファイルでは、話者IDはすべてデフォルト値となり、話者情報を手動で修正する必要があります。修正しない場合、吹き替え効果が期待通りにならない可能性があります。
フィードバック