使用组合解析提取模式采集日志
Download
聚焦模式
字号
注意:
Windows 系统环境暂不支持。
操作场景
当您的日志结构太过复杂,涉及多种解析模式,单种解析模式(如 Nginx 模式、完整正则模式、JSON 模式等)无法满足日志解析需求时,您可以使用 LogListener 组合解析格式解析日志,此模式支持用户在控制台输入代码(JSON 格式)用来定义日志解析的流水线逻辑。您可添加一个或多个 LogListener 插件处理配置,LogListener 会根据处理配置顺序逐一执行。本文为您介绍如何使用组合解析提取模式采集日志。
前提条件
目标文件所在服务器已安装 LogListener,详情请参见 LogListener 安装指南(Linux 版)。
LogListener Linux 版本为2.6.4以上。
效果预览
假设您的一条日志的原始数据为:
1571394459,http://127.0.0.1/my/course/4|10.135.46.111|200,status:DEAD
自定义插件内容如下:
{"processors": [{"type": "processor_split_delimiter","detail": {"Delimiter": ",","ExtractKeys": [ "time", "msg1","msg2"]},"processors": [{"type": "processor_timeformat","detail": {"KeepSource": true,"TimeFormat": "%s","SourceKey": "time"}},{"type": "processor_split_delimiter","detail": {"KeepSource": false,"Delimiter": "|","SourceKey": "msg1","ExtractKeys": [ "submsg1","submsg2","submsg3"]},"processors": []},{"type": "processor_split_key_value","detail": {"KeepSource": false,"Delimiter": ":","SourceKey": "msg2"}}]}]}
经过日志服务结构化处理后,该条日志将变为如下:
time: 1571394459submsg1: http://127.0.0.1/my/course/4submsg2: 10.135.46.111submsg3: 200status: DEAD
配置说明
自定义插件种类
插件功能 | 插件名称 | 功能 |
提取字段 | processor_log_string | 使用 processor_log_string 插件对字段进行多字符解析(换行符),一般用于单行日志的高级功能 |
提取字段 | processor_multiline | 使用 processor_multiline 插件(正则模式)对字段进行首行正则解析,一般用于多行日志的高级功能 |
提取字段 | processor_multiline_fullregex | 使用 processor_multiline_fullregex 插件(正则模式)对字段进行首行正则解析,一般用于多行日志的高级功能;并对多行日志进行正则提取 |
提取字段 | processor_fullregex | 使用 processor_fullregex 插件(正则模式)提取字段(单行日志) |
提取字段 | processor_json | 使用 processor_json 插件对字段值进行 JSON 展开 |
提取字段 | processor_split_delimiter | 使用 processor_split_delimiter 插件(单字符/多字符分隔符模式)提取字段 |
提取字段 | processor_split_key_value | 使用 processor_split_key_value 插件(键值对模式)提取字段 |
处理字段 | processor_drop | 使用 processor_drop 插件丢弃字段 |
处理字段 | processor_timeformat | 使用 processor_timeformat 插件,解析原始日志中的时间字段,用于转换时间格式,并可将解析结果设置为日志时间 |
自定义插件详细参数
插件名称 | 是否支持子项解析 | 插件参数 | 是否必须 | 功能 |
processor_multiline | 否 | BeginRegex | 是 | 定义多行日志的行首匹配正则 |
processor_multiline_fullregex | 是 | BeginRegex | 是 | 定义多行日志的行首匹配正则 |
| | ExtractRegex | 是 | 定义提取到多行日志后的提取正则 |
| | ExtractKeys | 是 | 定义提取键值 |
processor_fullregex | 是 | ExtractRegex | 是 | 定义提取正则 |
| | ExtractKeys | 是 | 定义提取键值 |
processor_json | 是 | SourceKey | 否 | 当前 processor 处理的上一级 processor 中的 key name |
| | KeepSource | 否 | 最终键值名称中,是否保留 SourceKey |
processor_split_delimiter | 是 | SourceKey | 否 | 当前 processor 处理的上一级 processor 中的 key name |
| | KeepSource | 否 | 最终键值名称中,是否保留 SourceKey |
| | Delimiter | 是 | 指定分隔符(单/多字符) |
| | ExtractKeys | 是 | 定义分隔符分割之后的提取键值 |
processor_split_key_value | 否 | SourceKey | 否 | 当前 processor 处理的上一级 processor 中的 key name |
| | KeepSource | 否 | 最终键值名称中,是否保留 SourceKey |
| | Delimiter | 是 | 定义字符串中 Key 与 Value 之间的分隔符 |
processor_drop | 否 | SourceKey | 是 | 当前 processor 处理的上一级 processor 中的 key name |
processor_timeformat | 否 | SourceKey | 是 | 当前 processor 处理的上一级 processor 中的 key name |
| | TimeFormat | 是 | 定义对 SourceKey 的值(日志中的时间数据字符串)的时间解析格式 |
操作步骤
步骤1:创建日志主题
如果您想创建新的日志主题,可执行如下操作:
1. 登录 日志服务控制台。
2. 在左侧导航栏中,选择概览,进入概览页面。
3. 在快速接入中,找到全部,单击云服务器 CVM,进入采集配置流程。

4. 在采集配置流程的创建日志主题页面,根据实际需求,输入日志主题名称,配置日志保存时间等信息,单击下一步。
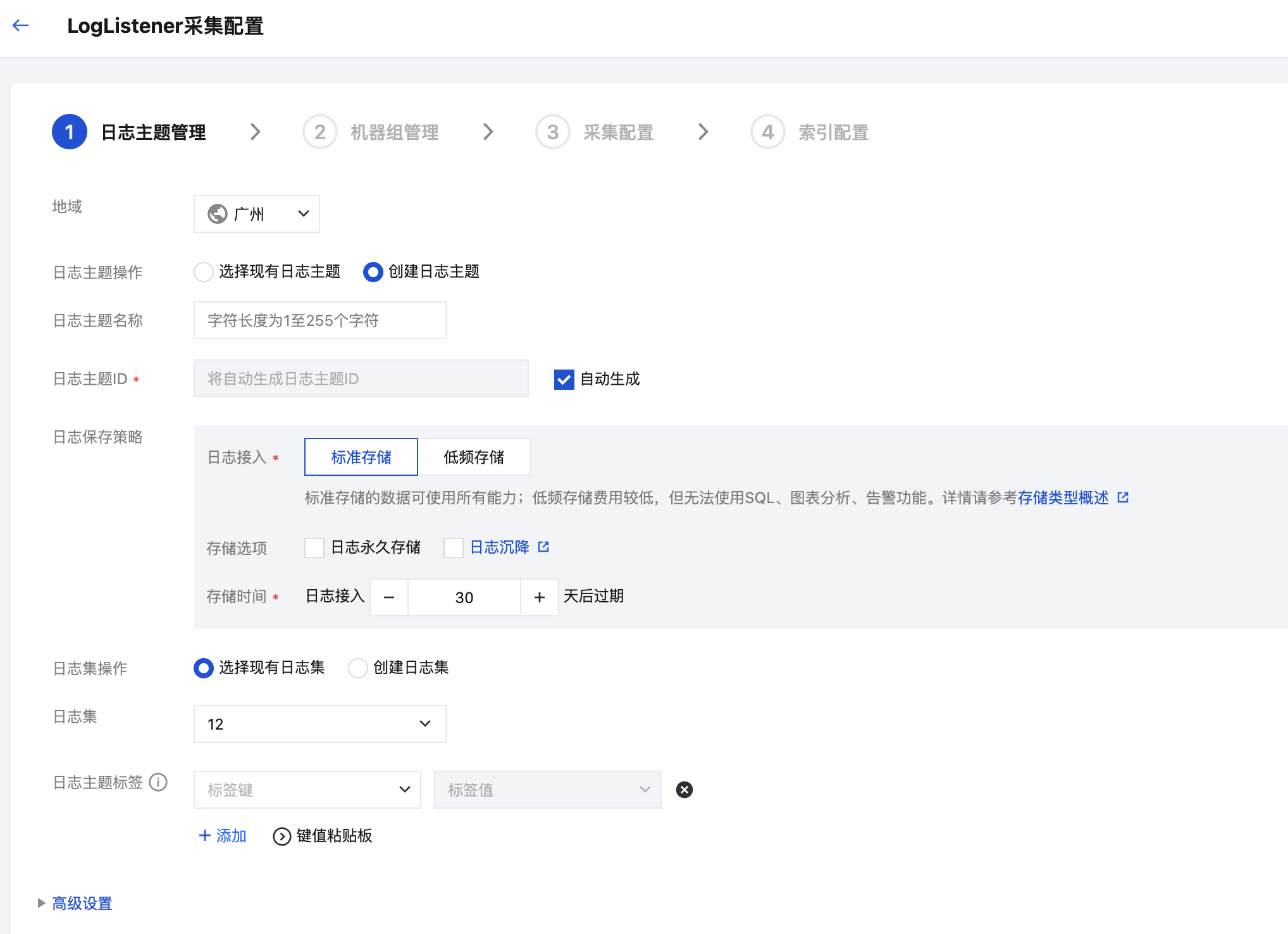
如果您想选择现有的日志主题,可执行如下操作:
1. 登录 日志服务控制台。
2. 在左侧导航栏中,选择日志主题,然后选择需要投递的日志主题,单击指定日志主题名称,进入日志主题管理页面。
3. 选择采集配置页签,在 LogListener 采集配置栏下单击新增,进入日志数据源选择。
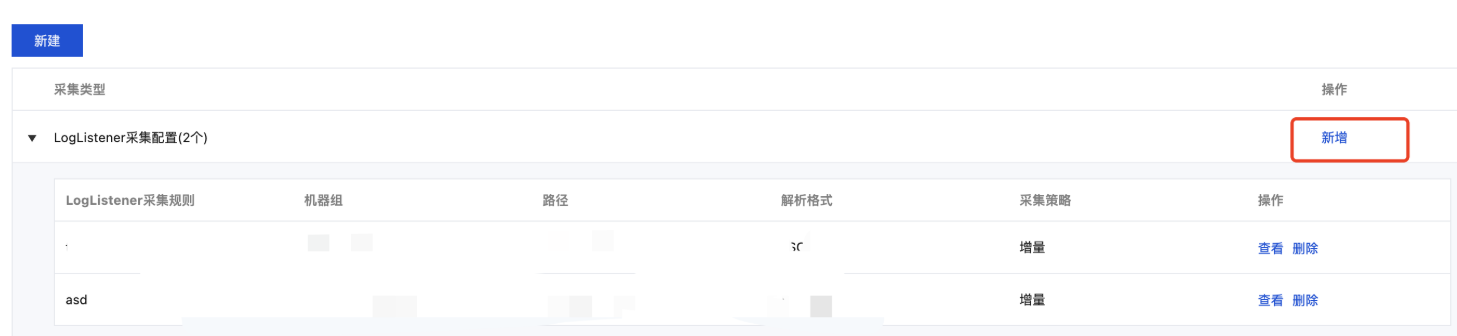
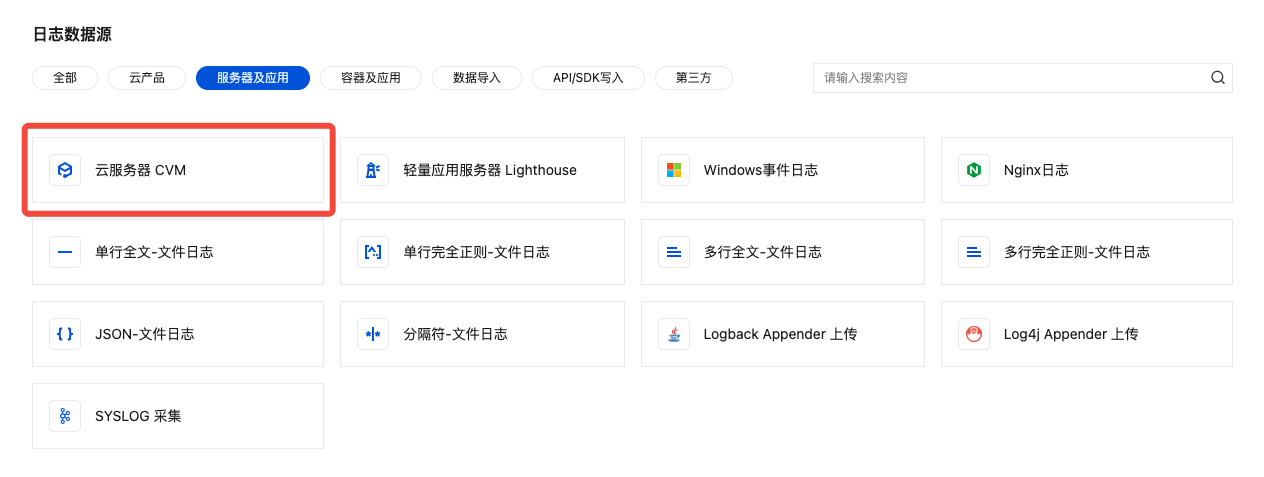
4. 在日志数据源选择页面中,选择服务器及应用,找到并单击云服务器 CVM,进入采集配置流程。
步骤2:管理机器组
如果您想创建新的机器组,可执行如下操作:
1. 单击新建机器组。
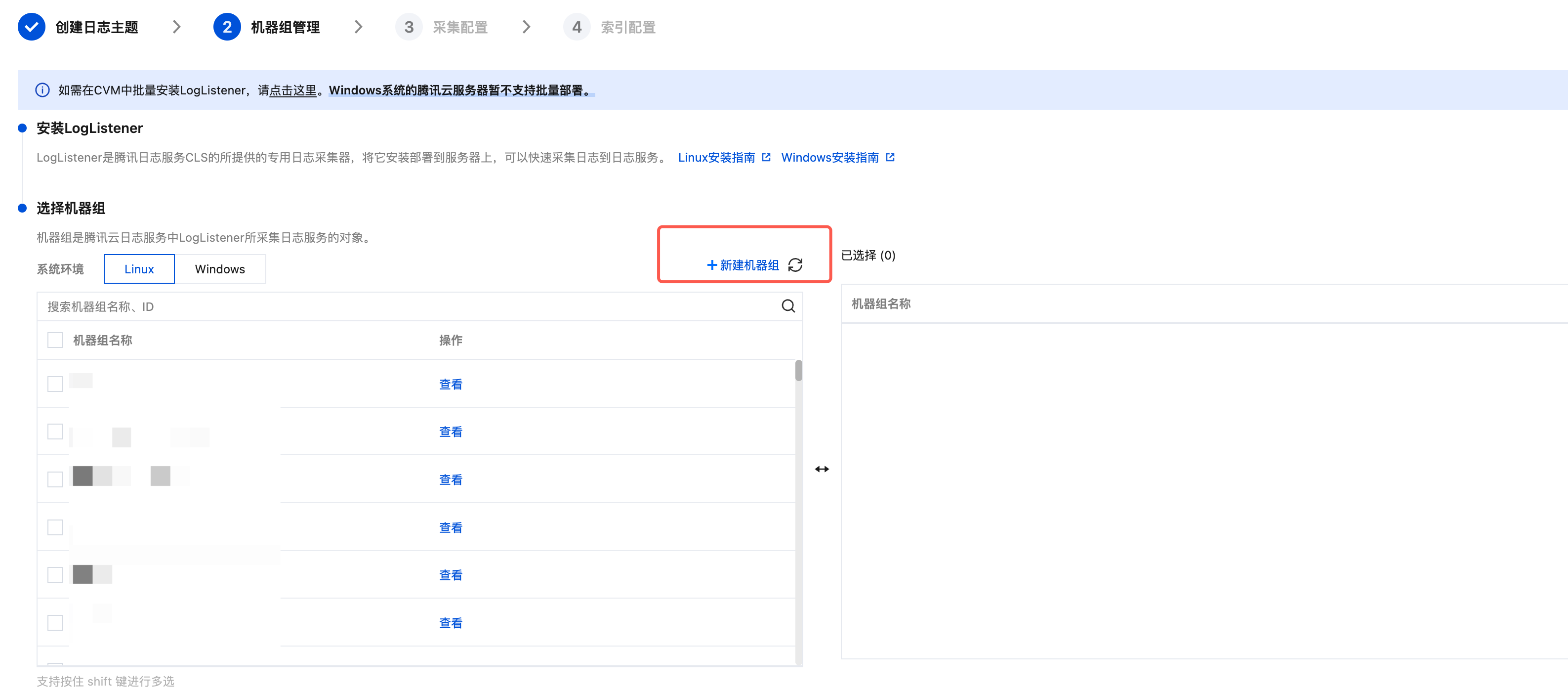
2. 填写机器组名称,通过机器标识的方式关联已安装 LogListener 的目标服务器。详情请参见 机器组,然后单击确定。
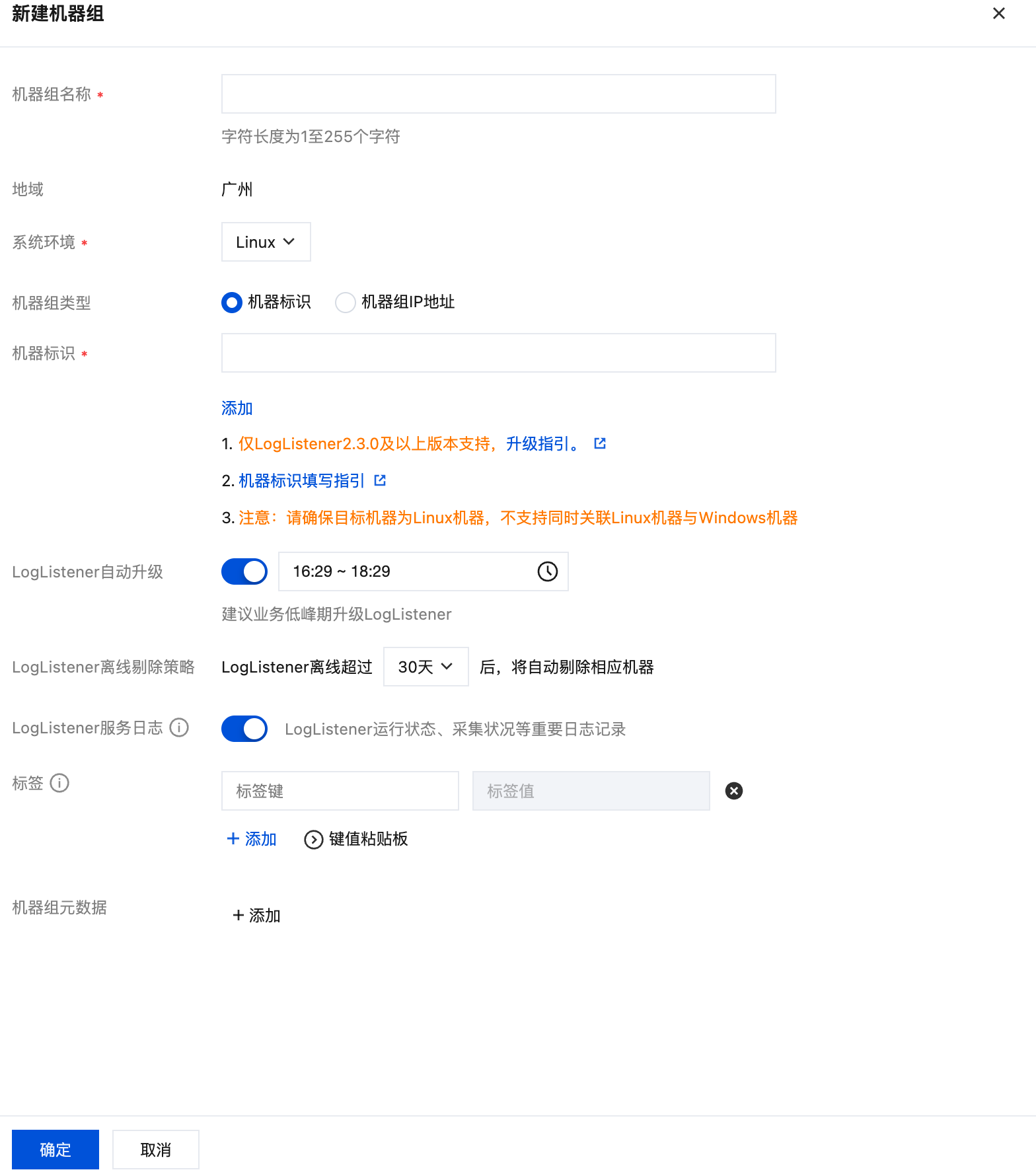
3. 完成创建后,在 Tab 选项中选择您创建的机器组的系统环境,在列表中勾选您的目标机器组,并单击下一步。
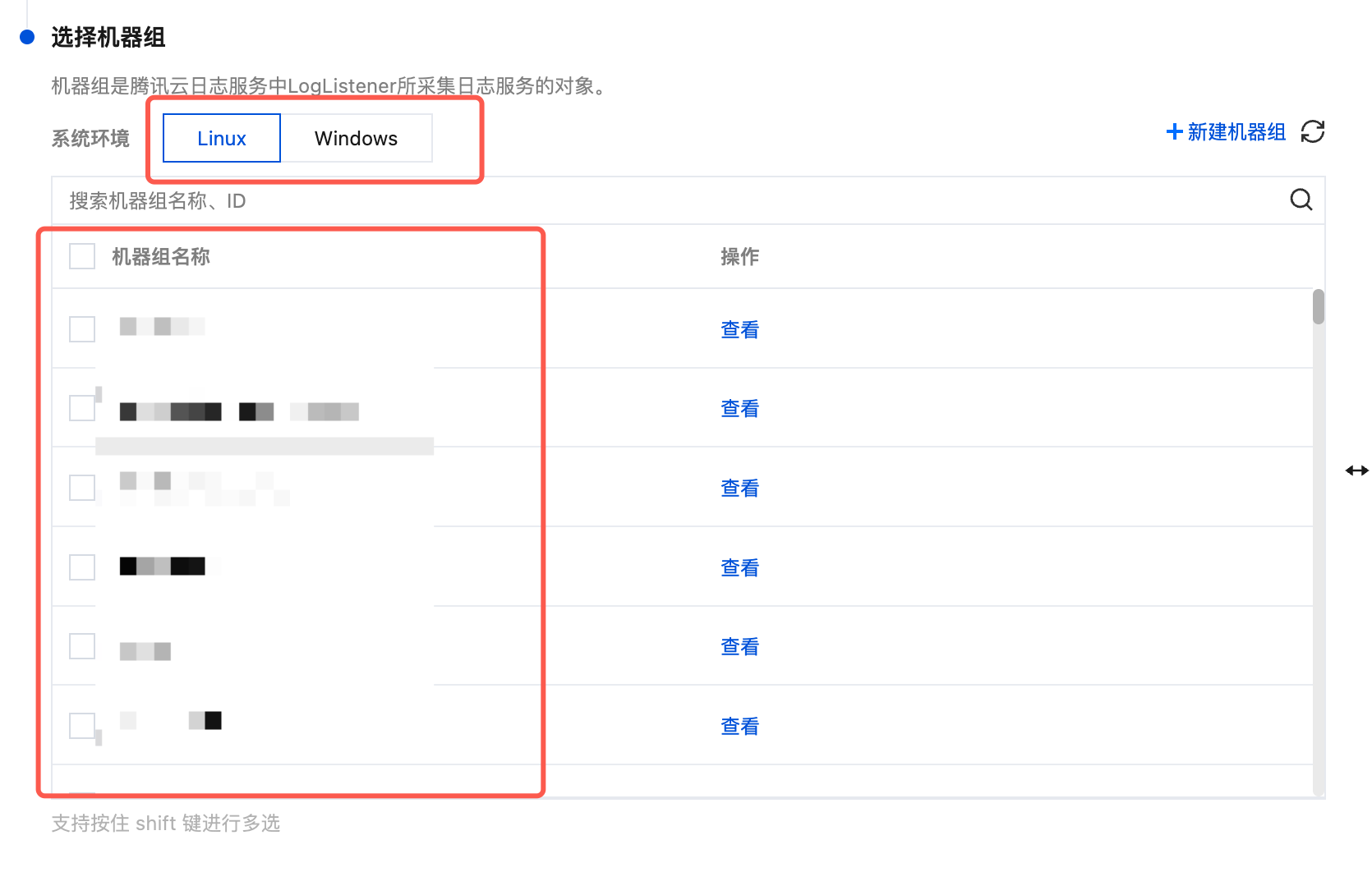
如果您想选择已有的机器组,可在 Tab 选项中选择您创建的机器组的系统环境,在列表中勾选您的目标机器组,并单击下一步。
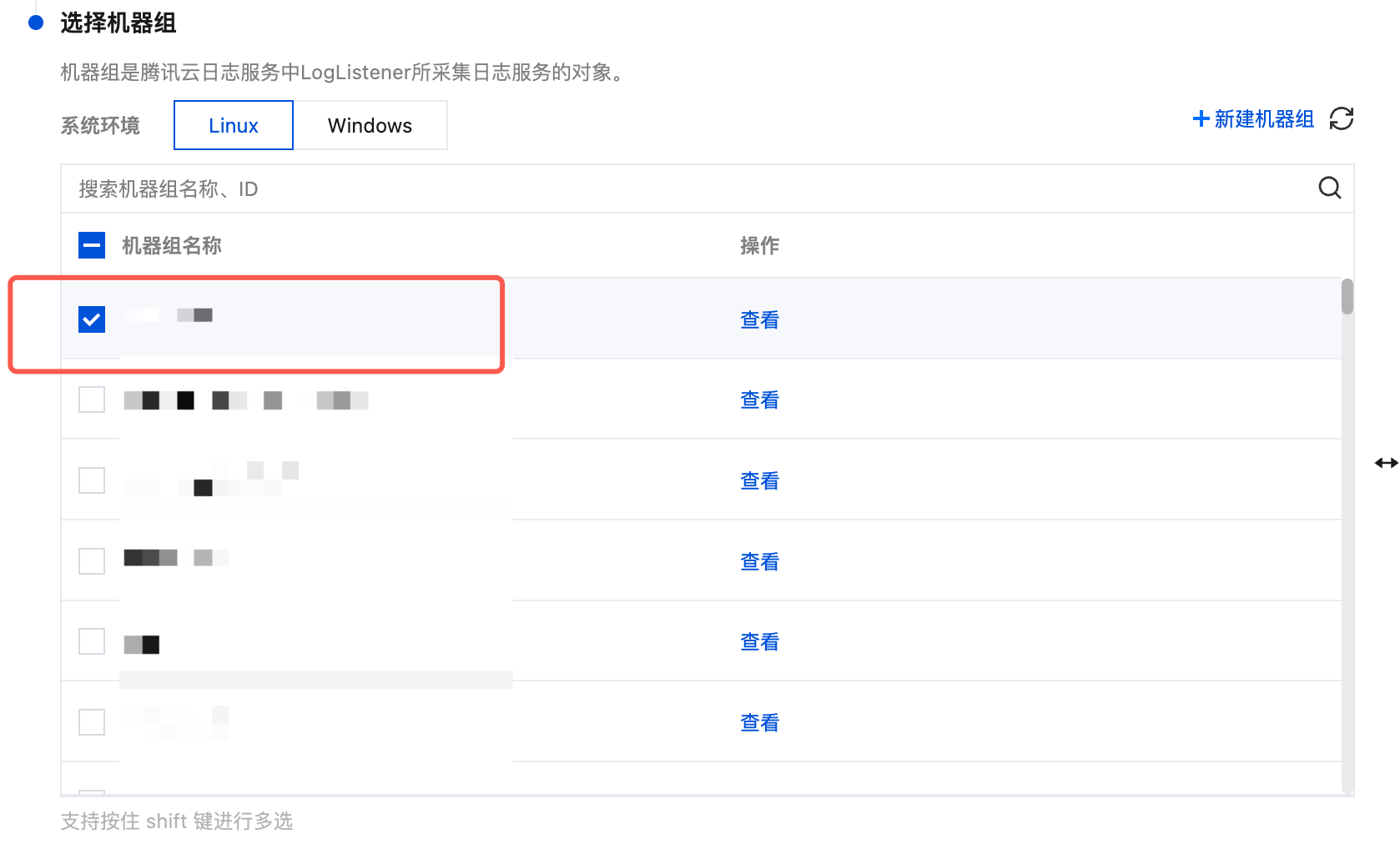
步骤3:采集配置
配置日志文件采集路径
在“采集配置”页面,根据日志采集路径格式,填写“采集路径”。如下图所示:
日志采集路径格式:
[目录前缀表达式]/**/[文件名表达式]。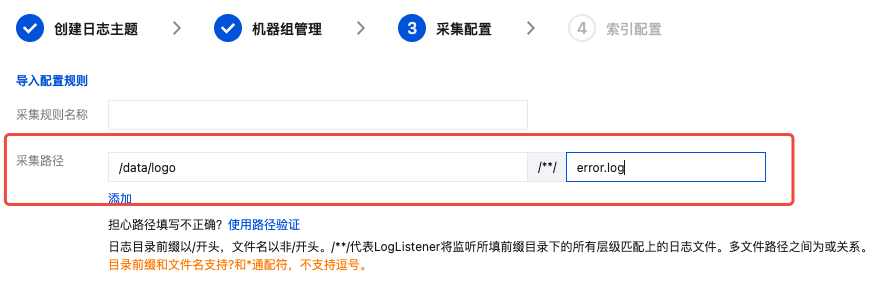
填写日志采集路径后,LogListener 会按照[目录前缀表达式]匹配所有符合规则的公共前缀路径,并监听这些目录(包含子层目录)下所有符合[文件名表达式]规则的日志文件。其参数详细说明如下:
字段 | 说明 |
目录前缀 | 日志文件前缀目录结构,仅支持通配符 * 和 ? ,* 表示匹配多个任意字符,? 表示匹配单个任意字符,不支持填写逗号。 |
/**/ | 表示当前目录以及所有子目录。 |
文件名 | 日志文件名,仅支持通配符 * 和 ? ,* 表示匹配多个任意字符,? 表示匹配单个任意字符,不支持填写逗号。 |
常用的配置模式如下:
[公共目录前缀]/**/[公共文件名前缀]*
[公共目录前缀]/**/*[公共文件名后缀]
[公共目录前缀]/**/[公共文件名前缀]*[公共文件名后缀]
[公共目录前缀]/**/*[公共字符串]*
填写示例如下:
序号 | 目录前缀表达式 | 文件名表达式 | 说明 |
1 | /var/log/nginx | access.log | 此例中,日志路径配置为 /var/log/nginx/**/access.log,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以access.log命名的日志文件 |
2 | /var/log/nginx | *.log | 此例中,日志路径配置为 /var/log/nginx/**/*.log,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以.log结尾的日志文件 |
3 | /var/log/nginx | error* | 此例中,日志路径配置为 /var/log/nginx/**/error*,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以error开头命名的日志文件 |
注意:
LogListener 2.3.9及以上版本才可以添加多个采集路径。
建议配置采集路径为
log/*.log,rename 日志轮转后的老文件命名为 log/*.log.xxxx。默认情况下,一个日志文件只能被一个日志主题采集。如果一个文件需要对应多个采集配置,请给源文件添加一个软链接,并将其加到另一组采集配置中。
配置采集路径黑名单
开启采集路径黑名单,可在采集时忽略指定的目录前缀或完整的文件路径。目录路径和文件路径可以是完全匹配,也支持通配符模式匹配。
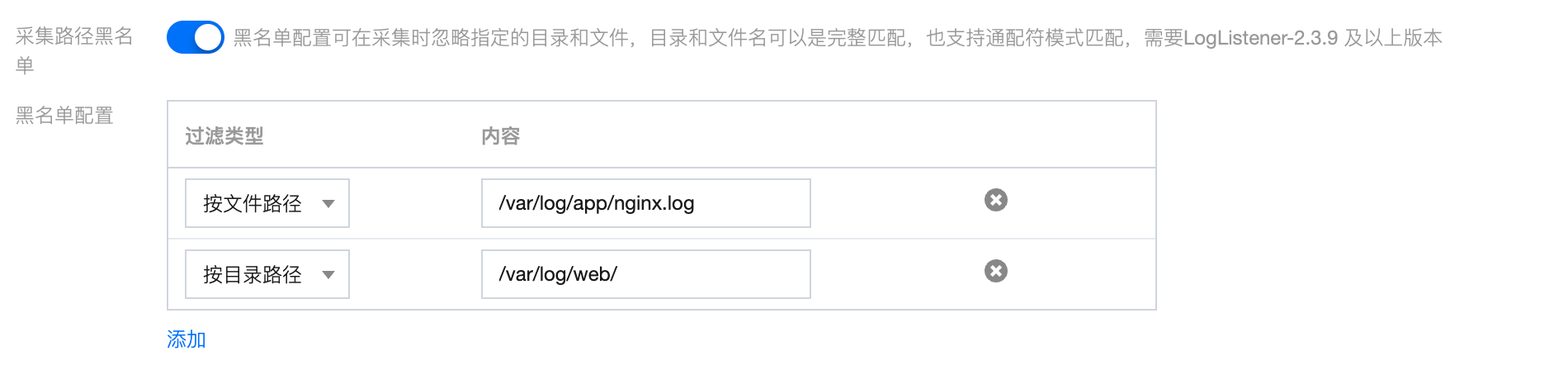
采集黑名单分为两类过滤类型,且可以同时使用:
文件路径:采集路径下,需要忽略采集的完整文件路径,支持通配符*或?,支持**路径模糊匹配。
目录路径:采集路径下,需要忽略采集的目录前缀,支持通配符*或?,支持**路径模糊匹配。
注意:
需要 LogListener 2.3.9及以上版本。
采集黑名单是在采集路径下进行排除,因此无论是文件路径模式,还是目录路径模式,其指定路径要求为采集路径的子集。
配置采集策略
全量采集:LogListener 采集文件时,从文件的开头开始读。
增量采集:LogListener 采集文件时,只采集文件内新增的内容。
配置回溯采集

当采集策略选择为增量采集时,您可以进一步在此设置回溯采集的起始点,指定 LogListener 启动时是否从最新位置往前偏移指定字节数开始采集。
注意:
Windows 系统环境暂不支持。
编码模式
UTF-8:若您的日志文件编码模式为 UTF-8,请选择该选项。
GBK:若您的日志文件编码模式为 GBK,请选择该选项。
配置组合解析模式
将提取模式设置为组合解析。如下图所示:

配置自定义元数据
注意:
LogListener 2.8.7及以上版本才可以配置自定义元数据。
机器组元数据:使用机器组元数据。
采集路径:通过正则提取采集路径中的值作为元数据。
自定义:自定义键值作为元数据。
配置上传解析失败日志
建议开启上传解析失败日志。开启后,LogListener 会上传各种解析失败的日志。若关闭上传解析失败日志,则会丢弃失败的日志。

开启后需要配置解析失败的 Key 值(默认为 LogParseFailure),所有解析失败的日志,均以输入内容作为键名称(Key),原始日志内容作为值(Value)进行上传。
上传原始日志
开启后 LogListener 会将原始日志与解析后的日志一起上传。所有原始日志,均以您指定的键名称,原始日志内容将作为值(Value)进行上传。
高级配置
通过勾选,选择您需要定义的高级配置。

组合解析提取模式下,支持配置以下高级配置。
名称 | 描述 | 配置项 |
超时属性 | 该配置控制日志文件的超时时间。如果一个日志文件在指定时间内没有任何更新,则为超时。超时的日志文件 LogListener 将不再采集。当您的日志文件数量较大时,建议缩短超时时间,避免 LogListener 性能浪费。 | 不超时:日志文件永不超时 自定义:自定义日志文件的超时时间 |
最大目录深度 | 该配置控制日志采集的最大目录深度。LogListener 不会采集所在目录层级超过指定最大目录深度的日志文件。当您目标采集路径包含模糊匹配时,建议配置合适的最大目录深度,避免 LogListener 性能浪费。 | 大于0的整数。0代表不进行子目录的下钻 |
步骤4:索引配置
1. 单击下一步,进入“索引配置”页面。
2. 在“索引配置”页面,设置如下信息。配置详情请参见 索引配置。
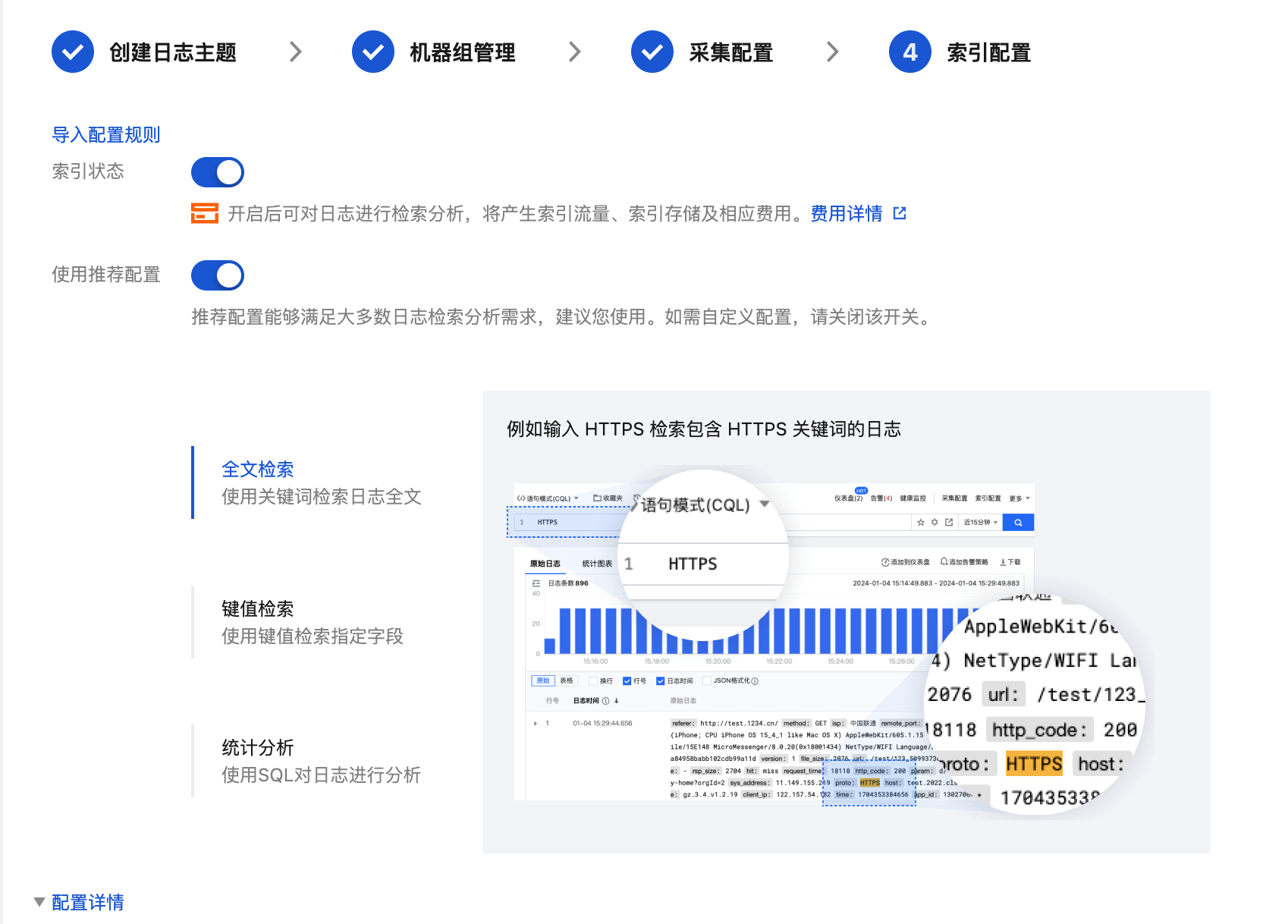
注意:
检索必须开启索引配置,否则无法检索。
3. 单击提交,进入编辑索引配置确认页面。
4. 操作成功,完成采集配置。
使用限制
使用组合解析模式解析数据时,LogListener 会需要消耗更多的资源,不建议您使用过于复杂的插件组合来处理数据。
使用组合解析模式后,文本模式使用采集功能、过滤器功能将失效,但其中部分功能可通过相关自定义插件实现。
使用组合解析模式后,上传解析失败日志功能默认开启,解析失败的日志均以输入名称为键(Key),原始日志内容作为值(Value)进行上传。
相关操作
检索日志
1. 登录 日志服务控制台。
2. 在左侧导航栏中,单击检索分析,进入检索分析页面。
3. 根据实际需求,选择地域、日志集与日志主题,即可开始按照设定的查询条件检索日志。
文档反馈