You can query, analyze, and compute the data in a created database or data table with SQL statements.
Running a SELECT query task
1. Select the default database and compute resource.
You can select a default database. Then, when there is no database specified in a SQL statement, the statement will be executed in the default database.
You can select a public or private cluster as the compute resource.
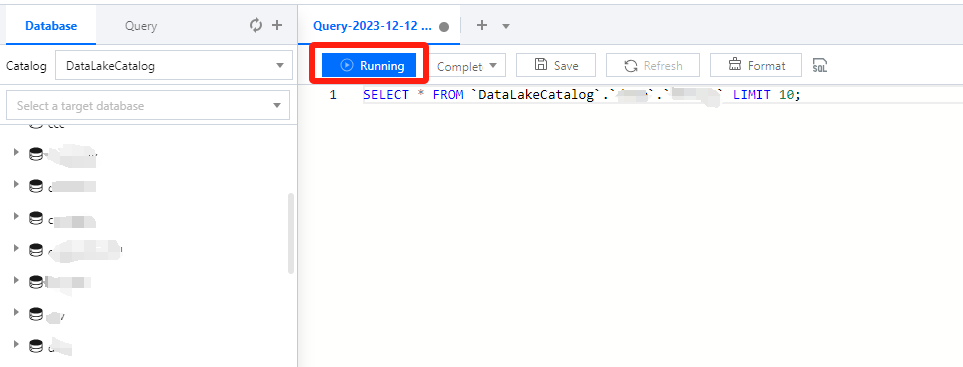
2. Write a standard SQL statement and click Running.
In Data Lake Compute, a task can run for up to 30 minutes.
Data Lake Compute is serverless, so compute resources will be scheduled temporarily. It may take longer than usual to return the result of the first DML task.
3. The query result will be displayed in the console after the task is completed.
If you exit the console page, you cannot view the query result of a historical task there again. In this case, you can view the task result file in Run history or the query result COS bucket you configured.
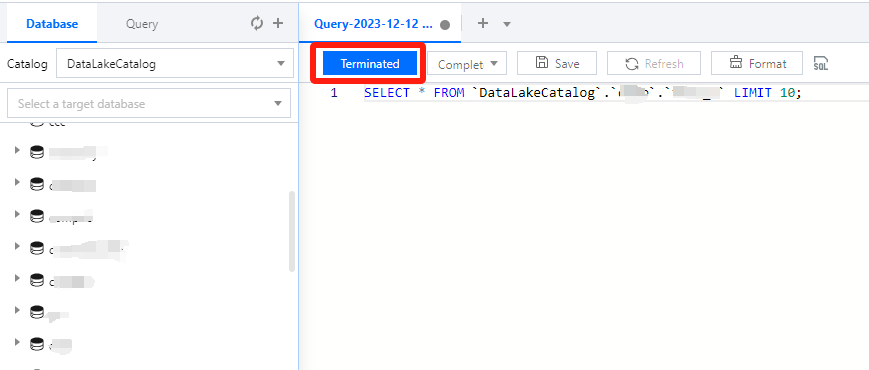
Canceling a running query task
During task running, the Run button becomes Terminated, which you can click to cancel the task. Then, Data Lake Compute will not return the query result but will calculate the scanned data volume. If you use the public engine, the scanned data volume will incur fees. For billing details, see Billing Overview.