低优 Pod 在调度到节点 GPU 上后,如果 GPU 算力没有被高优 Pod 占用,低优 Pod 可以完全使用 GPU 算力。多个低优 Pod 共享 GPU 算力会受到 qGPU policy 策略控制。多个高优 Pod 之间不受具体 policy 控制,会是争抢模式。
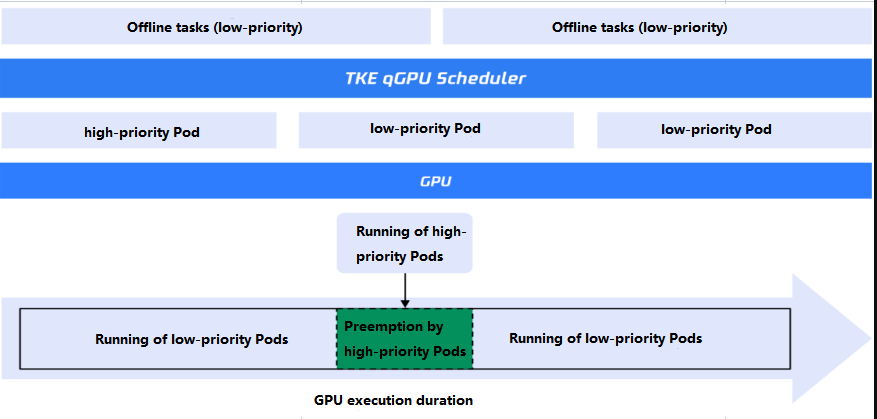
功能2:高优 Pod 可以100%抢占低优 Pod
qGPU 离在线混部提供了一种优先级抢占能力,可以保证高优 Pod 在忙时能立刻、完全使用 GPU 算力资源,这是通过一种优先级抢占调度策略实现的。我们在 qGPU 驱动层实现了这种绝对抢占能力:
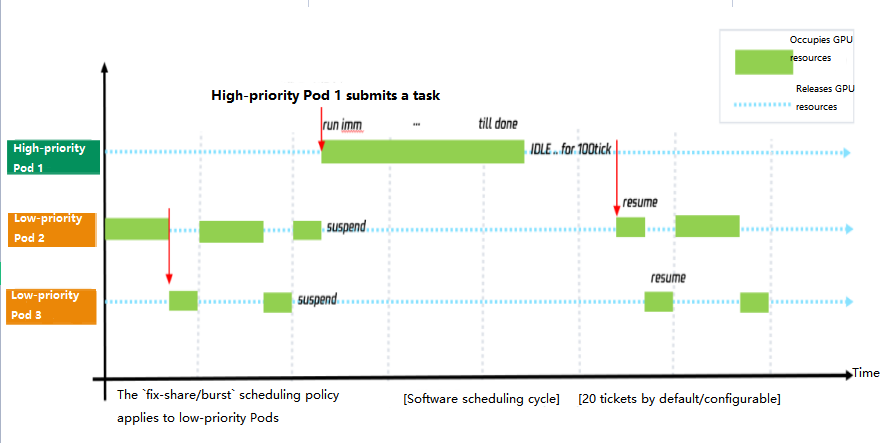
首先,qGPU 驱动可以感知高优 Pod 对 GPU 算力的需求。高优 Pod 一旦提交涉及 GPU 算力的计算任务,qGPU 驱动会在第一时间将算力全部提供给高优 Pod 使用,响应时间被控制在1ms以内。当高优 Pod 无任务运行时,驱动会在100ms后释放所占用算力,并重新分配给离线 Pod 使用。
其次,qGPU 驱动可以支持计算任务的暂停和继续。当高优 Pod 有计算任务运行时,原有占用 GPU 的低优 Pod 会立刻被暂停,将 GPU 算力让出,给高优 Pod 使用。当高优 Pod 任务结束,低优 Pod 会随即被唤醒,按照中断点继续计算。各优先级计算任务运行的时序图如下所示:
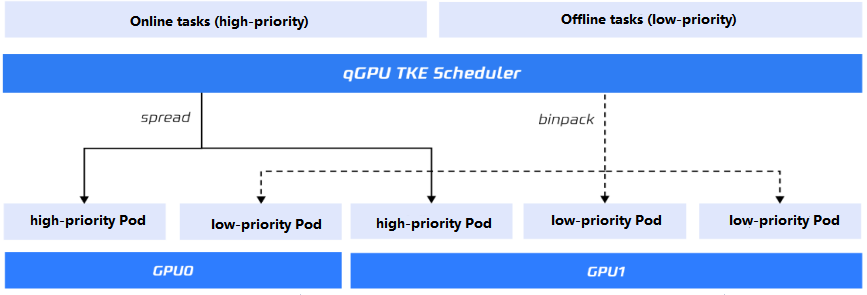
调度策略
在普通 qGPU 节点中,用户可以通过设置 policy 影响不同 Pod qGPU 在同一张卡上的调度策略。离在线混部功能中,policy 只会对低优 Pod 的调度产生影响。
低优 Pod
当前高优 Pod 处于休眠状态,低优 Pod 在运行,低优 Pod 之间仍会按照 policy 策略调度。当高优 Pod 开始使用 GPU 算力,所有低优 Pod 会立刻被暂停,直到高优 Pod 计算任务结束,低优任务会重新按照 policy 策略继续运行。
高优 Pod
高优 Pod 在有计算任务后会立即抢占 GPU 算力,高优 Pod 与低优 Pod 间是绝对抢占关系,不受具体 policy 影响。多个高优 Pods 之间的 GPU 算力分配是一种争抢模式,不受具体 policy 策略控制。