使用 qGPU
Download
聚焦模式
字号
使用须知
支持的 Kubernetes 版本 | TKE 版本 ≥ v1.14.x |
支持的节点类型 | |
支持的 GPU 卡架构 | 支持 Volta(如 V100 )、Turing(如 T4)、Ampere(如 A100、A10)、L40 (Pnv5i)、L40s (Pnv5)、Pnv5b、Pnv6。 |
支持的驱动版本 | nvidia 驱动小版本(末尾版本编号,举例450.102.04,这里小版本对应04)需满足如下条件: 450:<= 450.102.04 470:<= 470.161.03 515:<= 515.65.01 525:<= 525.89.02 |
共享粒度 | 每个 qGPU 最小分配1G显存,精度单位是1G。算力最小分配5(代表一张卡的5%),最大100(代表一张卡),精度单位是5(即5、10、15、20...100)。 |
整卡分配 | 开启了 qGPU 能力的节点可按照 tke.cloud.tencent.com/qgpu-core: 100 | 200 | ...(N * 100,N 是整卡个数)的方式分配整卡。建议通过 TKE 的节点池能力来区分 NVIDIA 分配方式或转换到 qGPU 使用方式。 |
个数限制 | 一个 GPU 上最多可创建16个 qGPU 设备。建议按照容器申请的显存大小确定单个 GPU 卡可共享部署的 qGPU 个数。 |
注意:
如果您升级了 TKE 集群的 Kubernetes Master 版本,请注意以下事项:
对于托管集群,您无需重新设置本插件。
对于独立集群(Master 自维护),Master 版本升级会重置 Master 上所有组件的配置,这将影响到 qgpu-scheduler 插件作为 Scheduler Extender 的配置。因此,您需要先卸载 qGPU 插件,然后再重新安装。
部署在集群内的 Kubernetes 对象
Kubernetes 对象名称 | 类型 | 请求资源 | Namespace |
qgpu-manager | DaemonSet | 每 GPU 节点一个 Memory: 300M, CPU:0.2 | kube-system |
qgpu-manager | ClusterRole | - | - |
qgpu-manager | ServiceAccount | - | kube-system |
qgpu-manager | ClusterRoleBinding | - | kube-system |
qgpu-scheduler | Deployment | 单一副本 Memory: 800M, CPU:1 | kube-system |
qgpu-scheduler | ClusterRole | - | - |
qgpu-scheduler | ClusterRoleBinding | - | kube-system |
qgpu-scheduler | ServiceAccount | - | kube-system |
qgpu-scheduler | Service | - | kube-system |
qGPU 权限
说明:
权限场景章节中仅列举了组件核心功能涉及到的相关权限,完整权限列表请参考权限定义章节。
权限说明
该组件权限是当前功能实现的最小权限依赖。
需要安装 qgpu ko 内核文件,创建、管理和删除 qgpu 设备,所以需要开启特权级容器。
权限场景
功能 | 涉及对象 | 涉及操作权限 |
跟踪 pod 的状态变化,获取 pod 信息,以及在 pod 删除时清理 qgpu 设备等资源。 | pods | get/list/watch |
跟踪 node 的状态变化,获取 node 信息,并根据 gpu 卡驱动和版本信息以及 qgpu 版本信息给 nodes 增加 label。 | nodes | get/list/watch/update |
qgpu-scheduler 是基于 kubernetes 调度器 extender 机制开发的针对 qgpu 资源的扩展调度器,需要的权限与社区其他调度类组件(如 volcano)相同,包括跟踪和获取 pods 信息,需要把调度结果更新到 pod 的 label 和 annotation,跟踪和获取 node 信息,跟踪获取配置的 configmap,创建调度事件。 | pods | get/list/update/patch |
| nodes | get/list/watch |
| configmaps | get/list/watch |
| events | create/patch |
gpu.elasticgpu.io 是 qgpu 的记录 gpu 资源信息的自定义 CRD 资源(该功能已废弃,但为了兼容旧版本,资源定义需要保留),由 qgpu-manager 及 qgpu-scheduler 管理,需要增删改查所有权限。 | gpu.elasticgpu.io 及 gpu.elasticgpu.io/status | 所有权限 |
权限定义
kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: qgpu-managerrules:- apiGroups:- ""resources:- podsverbs:- get- list- watch- apiGroups:- ""resources:- nodesverbs:- update- get- list- watch- apiGroups:- "elasticgpu.io"resources:- gpus- gpus/statusverbs:- '*'---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata:name: qgpu-schedulerrules:- apiGroups:- ""resources:- nodesverbs:- get- list- watch- apiGroups:- ""resources:- eventsverbs:- create- patch- apiGroups:- ""resources:- podsverbs:- update- patch- get- list- watch- apiGroups:- ""resources:- bindings- pods/bindingverbs:- create- apiGroups:- ""resources:- configmapsverbs:- get- list- watch- apiGroups:- "elasticgpu.io"resources:- gpus- gpus/statusverbs:- '*'
操作步骤
步骤1:安装 qGPU 调度组件
1. 登录 容器服务控制台,在左侧导航栏中选择集群。
2. 在集群列表中,单击目标集群 ID,进入集群详情页。
3. 选择左侧菜单栏中的组件管理,在组件管理页面单击新建。
4. 在新建组件管理页面中勾选 QGPU(GPU 隔离组件)。
5. 单击参数配置,设置 qgpu-scheduler 的调度策略。
Spread:多个 Pod 会分散在不同节点、不同显卡上,优先选择资源剩余量较多的节点,适用于高可用场景,避免把同一个应用的副本放到同一个设备上。
Binpack:多个 Pod 会优先使用同一个节点,适用于提高 GPU 利用率的场景。
6. 单击完成即可创建组件。安装成功后,需要为集群准备 GPU 资源。
步骤2:准备 GPU 资源并开启 qGPU 共享
1. 在集群列表中,单击目标集群 ID,进入集群详情页。
2. 在节点管理 > Worker节点中,选择节点池页签,单击新建。
3. 选择原生节点,单击创建。
4. 在新建页面,选择对应 GPU 机型并选择 qgpu 支持的驱动版本,如下图所示:
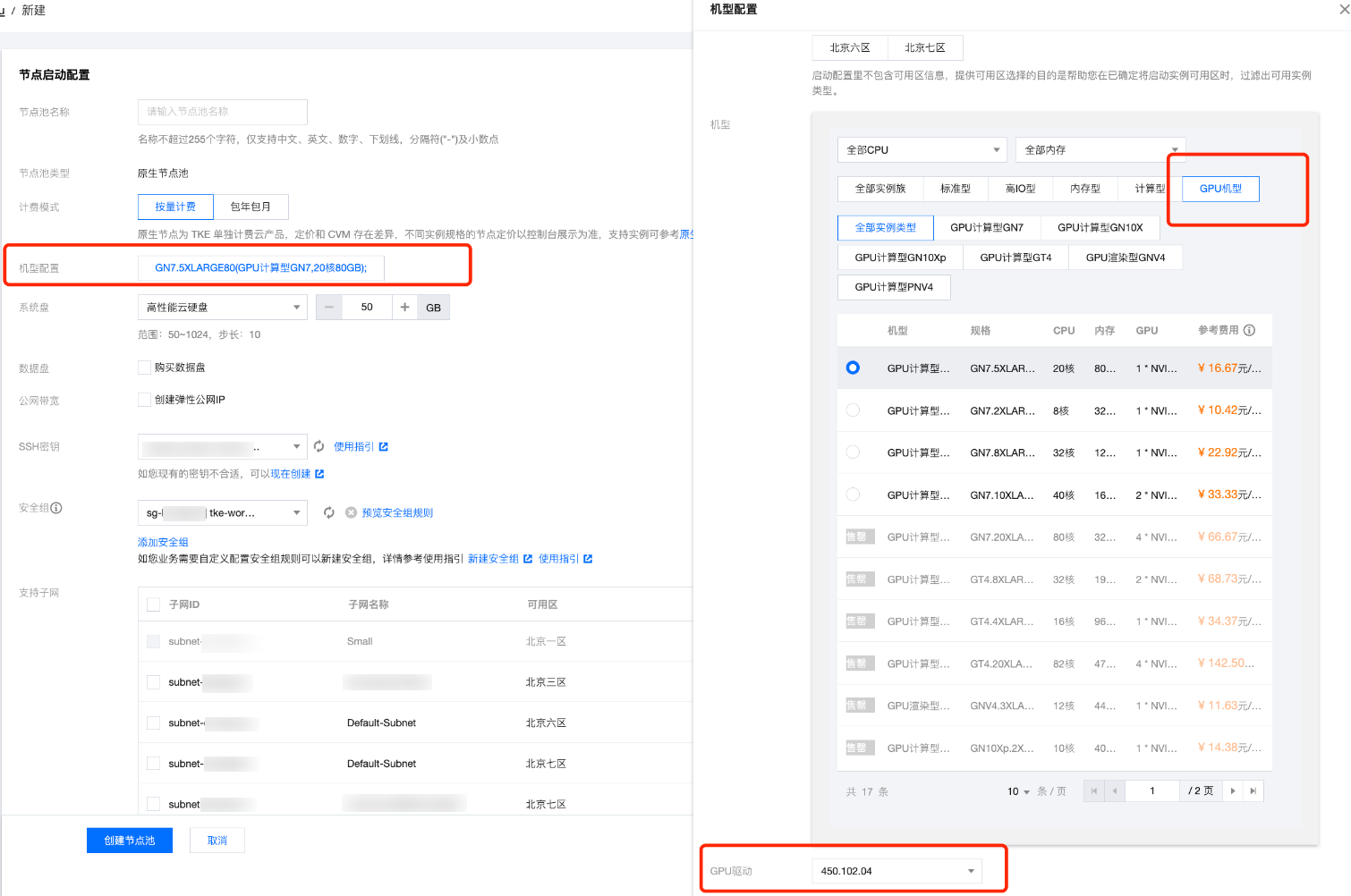
5. 在运维功能设置中,单击 qGPU 共享右侧开关。开关开启后,节点池中所有新增 GPU 原生节点默认开启 GPU 共享能力。您可以通过 Label 控制是否开启隔离能力。
6. 在高级设置 > Labels 中,通过节点池的高级配置来设置 Label,指定 qGPU 隔离策略:

Label 键:
tke.cloud.tencent.com/qgpu-schedule-policyLabel 值:
fixed-share(Label value 可填写全称或者缩写,更多取值可参考下方表格)
当前 qGPU 支持以下隔离策略:Label 值 | 缩写 | 英文名 | 中文名 | 含义 |
best-effort (默认值) | be | Best Effort | 争抢模式 | 默认值。各个 Pods 不限制算力,只要卡上有剩余算力就可使用。 如果一共启动 N 个 Pods,每个 Pod 负载都很重,则最终结果就是 1/N 的算力。 |
fixed-share | fs | Fixed Share | 固定配额 | 每个 Pod 有固定的算力配额,无法超过固定配额,即使 GPU 还有空闲算力。 |
burst-share | bs | Guaranteed Share with Burst | 保证配额加弹性能力 | 调度器保证每个 Pod 有保底的算力配额,但只要 GPU 还有空闲算力,就可被 Pod 使用。例如,当 GPU 有空闲算力时(没有分配给其他 Pod),Pod 可以使用超过它的配额的算力。注意,当它所占用的这部分空闲算力再次被分配出去时,Pod 会回退到它的算力配额。 |
7. 单击创建节点池。
步骤3:给应用分配共享 GPU 资源
通过给容器设置 qGPU 对应资源可以允许 Pod 使用 qGPU,您可以通过控制台或者 YAML 方式为应用分配 GPU 资源。
说明:
如果应用需要使用整数卡资源,只需填写卡数,无需填写显存(自动使用分配的 GPU 卡上全部显存)。
如果应用需要使用小数卡资源(即和其他应用共享同一张卡),需要同时填写卡数和显存。
1. 在集群的左侧导航栏选择工作负载,在任意工作负载对象类型页面单击新建。本文以 Deployment 为例。
2. 在新建 Deployment 页面,选择实例内容器,并填写 GPU 相关资源,如下图所示:

通过 YAML 来设置相关 qGPU 资源:
spec:containers:resources:limits:tke.cloud.tencent.com/qgpu-memory: "5"tke.cloud.tencent.com/qgpu-core: "30"requests:tke.cloud.tencent.com/qgpu-memory: "5"tke.cloud.tencent.com/qgpu-core: "30"
其中:
requests 和 limits 中和 qGPU 相关的资源值必须一致(根据 K8S 的规则,可以省略掉 requests 中对 qGPU 的设置,这种情况下 requests 会被自动设置为和 limits 相同的值)。
tke.cloud.tencent.com/qgpu-memory 表示容器申请的显存(单位G),整数分配,不支持小数。
tke.cloud.tencent.com/qgpu-core 代表容器申请的算力,每个 GPU 卡可以提供100%算力,qgpu-core 的设置应该小于100,设置值超过剩余算力比例值,则设置失败,设置后容器可以得到一张 GPU 卡 n% 的算力。
文档反馈