Apache Flume is a distributed, reliable, and available log collection system that supports a variety of data sources (such as HTTP, log files, JMS, and listening ports). It can efficiently collect, aggregate, and move massive log data from these data sources, and finally store the data in a specified storage system (such as Kafka, distributed file systems, or the Solr search servers).
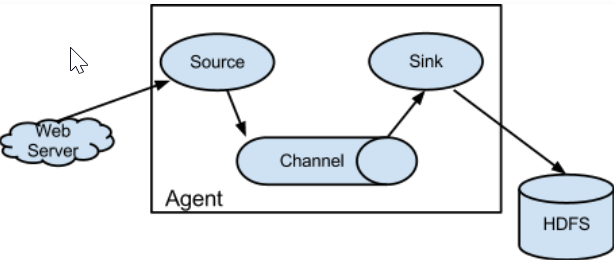
Flume is structured as follows:
Agents are the smallest units that run independently in Flume. An agent is a JVM composed of three main components: source, sink, and channel.
Flume and Kafka
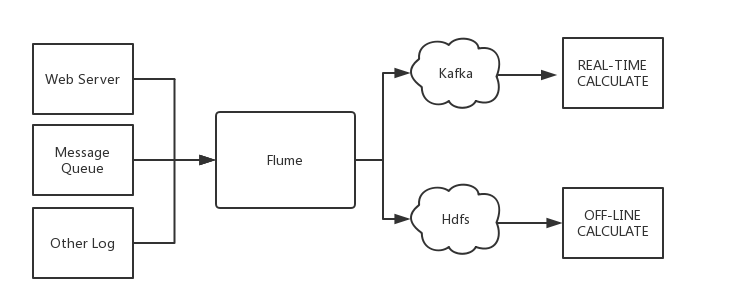
When you store data in a downstream storage module or compute module such as HDFS or HBase, you need to consider various complex factors such as the number of concurrent writes, system load, and network latency. As a flexible distributed system, Flume provides various APIs and customizable pipelines.
In the production process, Kafka can act as a cache when production and processing are at different paces. It has a high throughput because of the partition structure and data appending feature. It is also highly fault-tolerant because of the replication structure.
Therefore, Flume and Kafka can work together to meet most requirements in production environments.
Accessing Apache Kafka via Flume
Preparations
Download Apache Flume (version 1.6.0 or later is compatible with Kafka).
Download Kafka toolkit (version 0.9.x or later is required, as version 0.8 is no longer supported).
Confirm that Kafka's source and sink components are already in Flume.
Access Method
Kafka can be used as a source or sink to import or export messages.
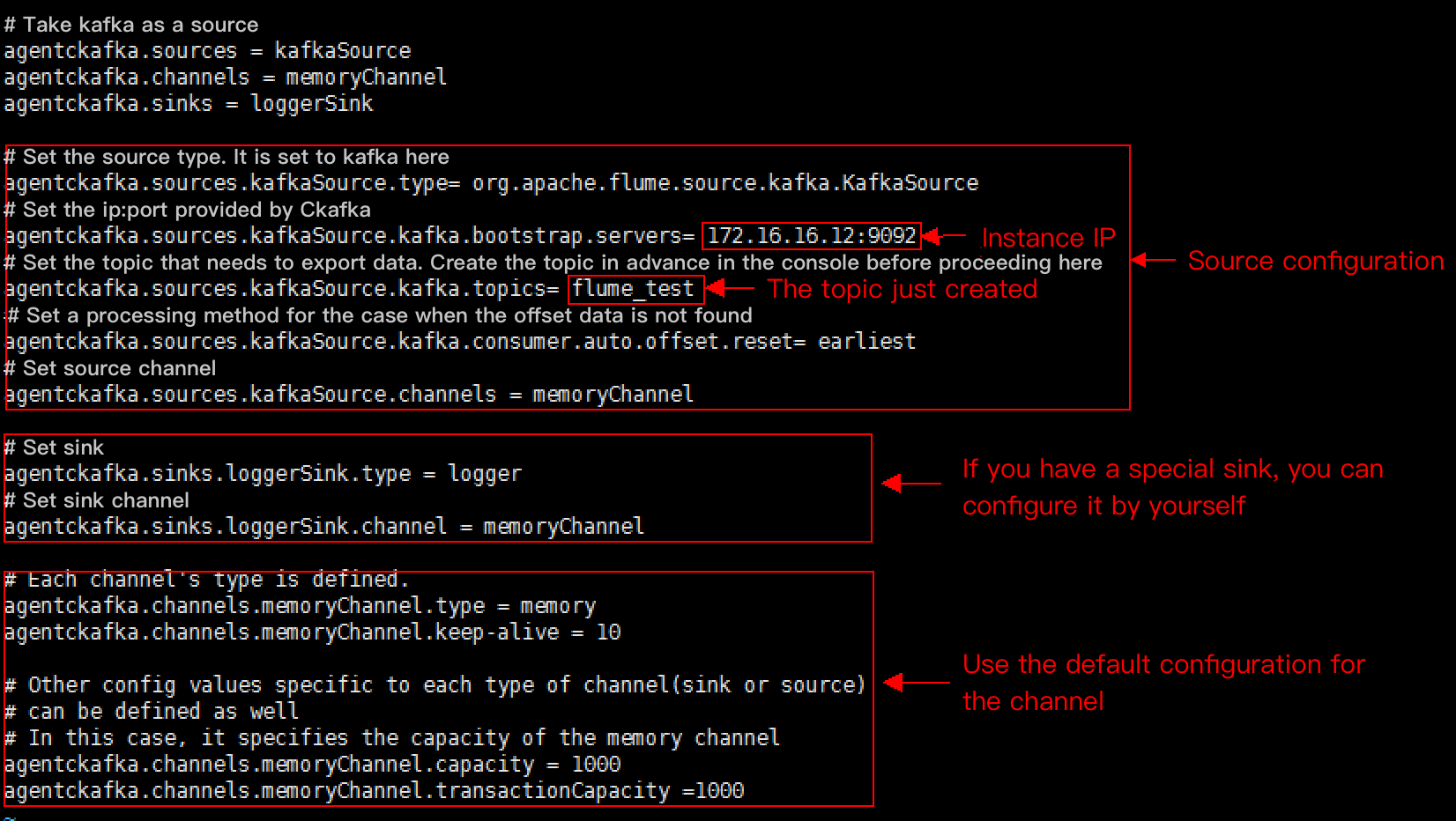
Kafka Source
Kafka Sink
Configure Kafka as the message source, that is, pull data as a consumer from Kafka into a specified sink. The main configuration items are as follows:
Configure Kafka as the message recipient, that is, push data to the Kafka server as a producer for subsequent operations. The main configuration items are as follows:
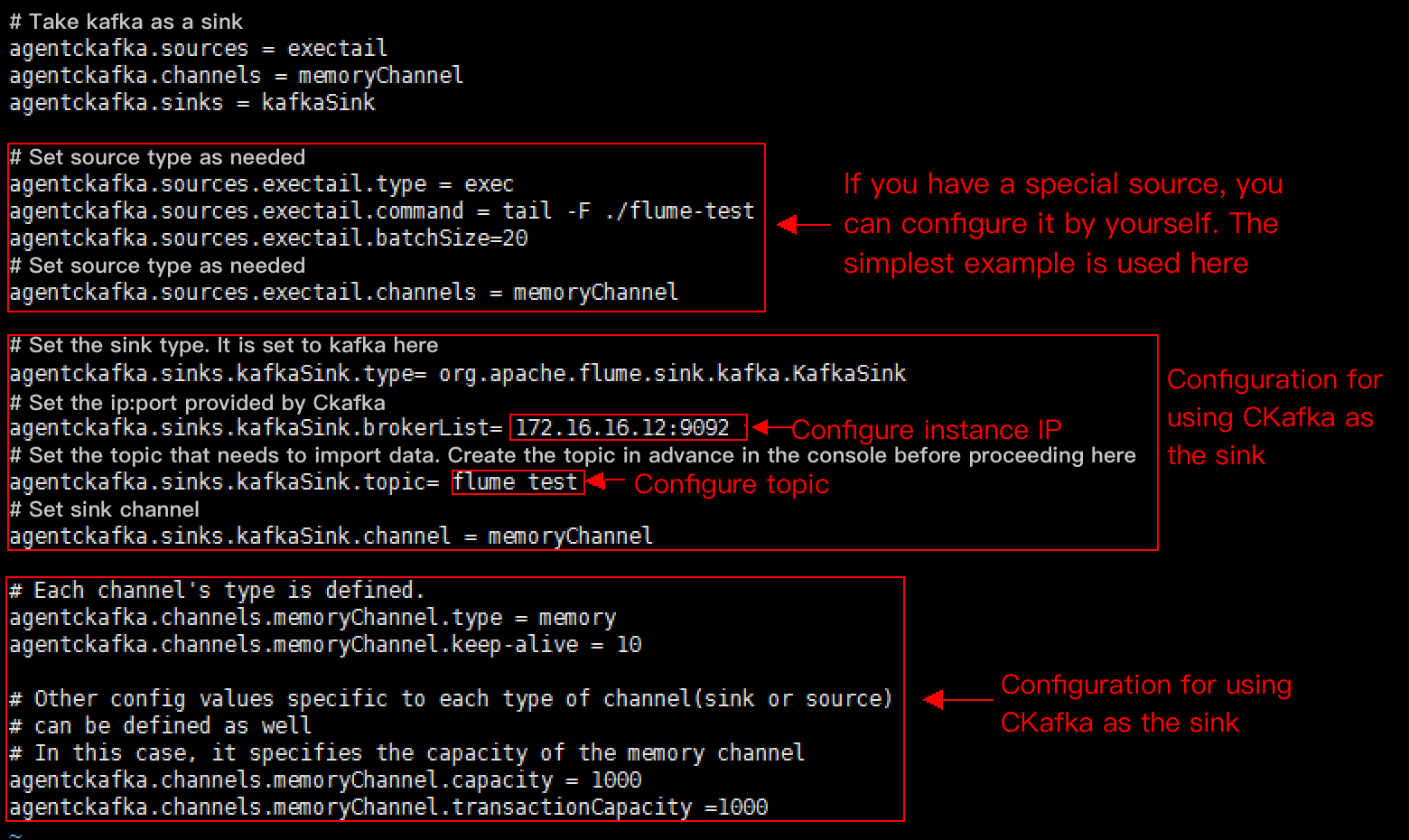
2. Write the configuration file flume-kafka-sink.properties. Below is a simple demo (configured in the conf folder in the decompressed directory) for Java. If there is no special requirement, simply replace the IP address and topic in the configuration file with your own instance IP address and topic. In this demo, the source is tail -F flume-test, which is the added information in the file.
The sample code is as follows:
# Demofor using Kafka as the sink.
agentckafka.source = exectail
agentckafka.channels = memoryChannel
agentckafka.sinks = kafkaSink
# Set the source type based on different requirements. For a special source, you can configure it yourself. Inthiscase, we use the simplest example.
2. Write the configuration file flume-kafka-source.properties. Below is a simple demo (configured in the conf folder in the decompressed directory). If there is no special requirement, simply replace the IP address and topic in the configuration file with your own instance IP address and topic. The sink is logger in this example.