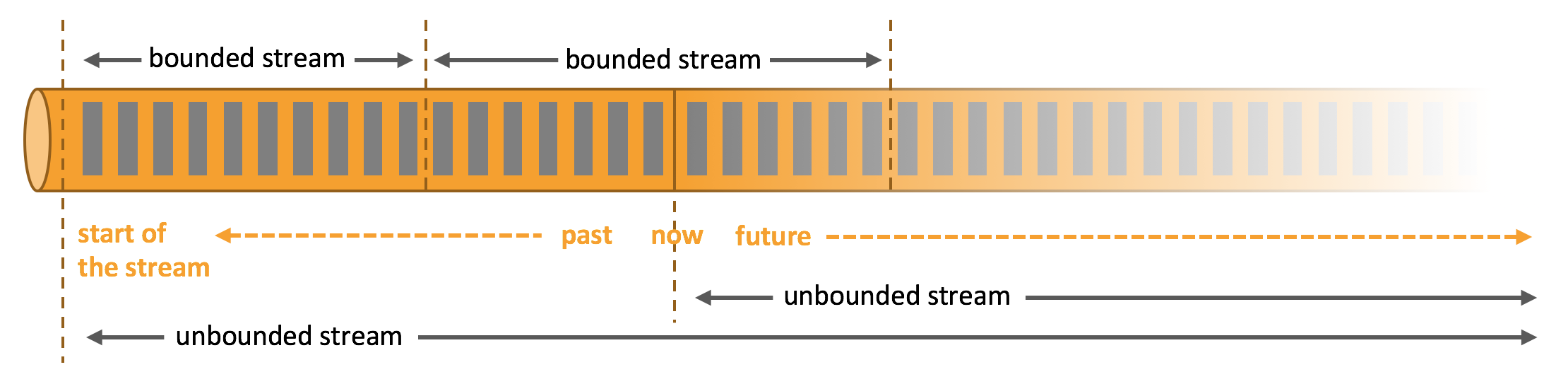
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments and perform computations at memory speed and at any scale.
Apache Flink excels at processing unbounded and bounded data sets. Precise control of time and status enables Flink’s runtime to run any kind of application on unbounded streams. Bounded streams are internally processed by algorithms and data structures that are specifically designed for fixed-sized data sets, yielding excellent performance.
Apache Flink requires real-time data from various sources (message queues or distributed logs such as Apache Kafka or Kinesis) in order to execute applications. Flink provides Apache Kafka connectors for reading data from or writing data to Kafka topics, which offer exactly-once processing semantics.
Operation Steps
Step 1: Obtaining the CKafka Instance Access Address
2. In the left sidebar, select Instance List and click the ID of the target instance to go to the basic instance information page.
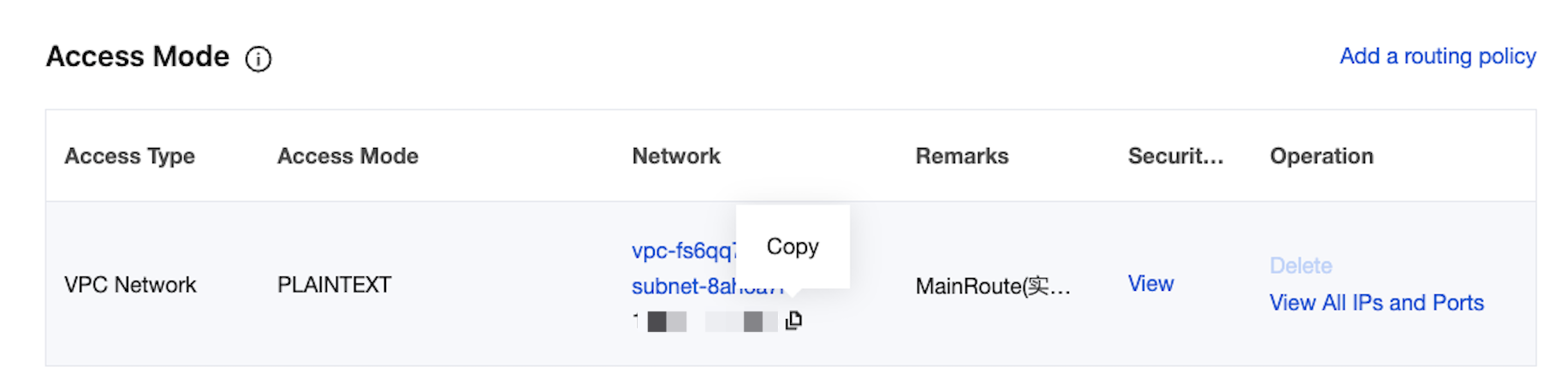
3. In the Access Mode module on the basic instance information page, obtain the instance access address, which is the bootstrap-server required for production and consumption.
Step 2: Creating a Topic
1. On the basic instance information page, select the Topic Management tab at the top.
2. On the topic management page, click New to create a topic named test. This topic is used as an example below to describe how to consume messages.
//Domain name address for public network access, that is, public routing address, which can be obtained in the Access Method module of the instance details page.
//Domain name address for public network access, that is, public routing address, which can be obtained in the Access Method module of the instance details page.