Generally, qGPU Pods fairly use physical GPU resources, and a qGPU kernel driver allocates equivalent GPU time slices to each task. As different GPU computing tasks have different running characteristics and importance levels, they have different requirements for GPU resources and use the resources differently. For example, real-time inference is sensitive to GPU resources and latency. It needs to get GPU resources as quickly as possible for computing, but the utilization is usually low. Model training requires a large amount of GPU resources but is insensitive to latency, which means it can endure a certain period of suppression.
Again this backdrop, Tencent Cloud has launched qGPU online/offline hybrid deployment, an innovative technology for deploying and scheduling online and offline GPU resources. Specifically, both online (high-priority) and offline (low-priority) tasks are deployed on the same GPU card, guaranteeing 100% utilization of the idle computing power by low-priority tasks and absolute preemption by high-priority tasks at the kernel and driver levels. This technology achieves 100% GPU utilization and minimizes costs.
Strengths
qGPU online/offline hybrid deployment keeps GPU computing power under absolute control and pushes the utilization to the limit:
100% utilization of the idle computing power of high-priority tasks: All GPU computing power can be used by low-priority tasks when it is not occupied by high-priority tasks.
100% preemption of the computing power of low-priority tasks: Busy high-priority tasks can preempt GPU computing power from low-priority tasks.
Typical Use Cases
Hybrid deployment of online and offline inference
Search and recommendation support online services and are sensitive to the real-timeness of GPU computing power, while data preprocessing supports offline data cleansing and processing and is insensitive to the real-timeness of GPU computing power. The former can be set as a high-priority task and the latter as a low-priority one for deployment on the same GPU card.
Hybrid deployment of online inference and offline training
Real-time reference is sensitive to the availability of GPU computing power and uses a relatively small amount of resources, while model training consumes a large amount of resources and is insensitive to the availability of GPU computing power. Therefore, the former can be set as a high-priority task and the latter as a low-priority one for deployment on the same GPU card.
How It Works
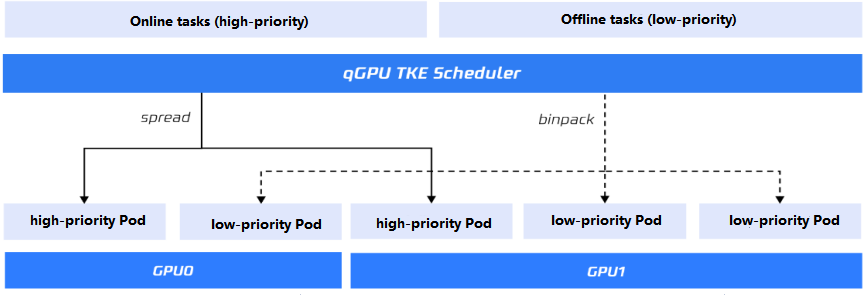
qGPU online/offline hybrid deployment can be enabled through the online/offline scheduling policy of the TKE cluster to allow online (high-priority) and offline (low-priority) tasks to share physical GPU resources more efficiently. qGPU online/offline hybrid deployment technology has two features:
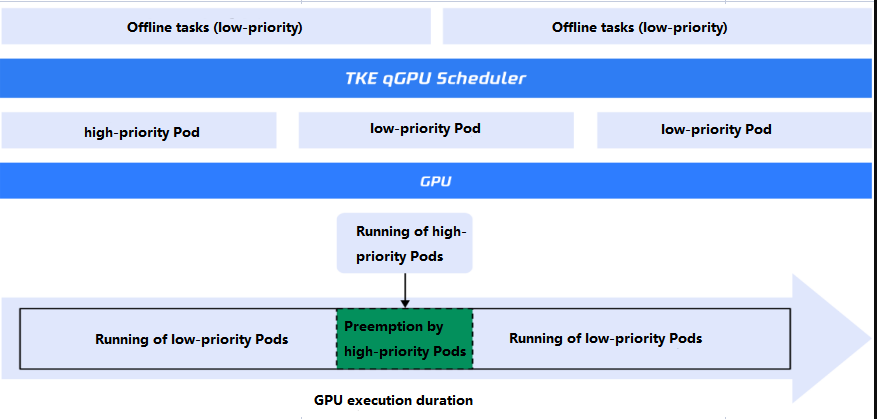
Feature 1: 100% utilization of the idle computing power by low-priority Pods
After low-priority Pods are scheduled to the node GPU, if the GPU computing power is not occupied by high-priority Pods, low-priority Pods can use all the computing power. When multiple low-priority Pods share the GPU computing power, the qGPU policy applies. When there are multiple high-priority Pods, resource competition applies instead of a specific policy.
Feature 2: 100% preemption of the computing power of low-priority Pods
qGPU online/offline hybrid deployment provides a priority-based preemption capability, which ensures that high-priority Pods can immediately and completely use the GPU computing power when they are busy. This is implemented through a priority-based preemption and scheduling policy at the qGPU driver layer:
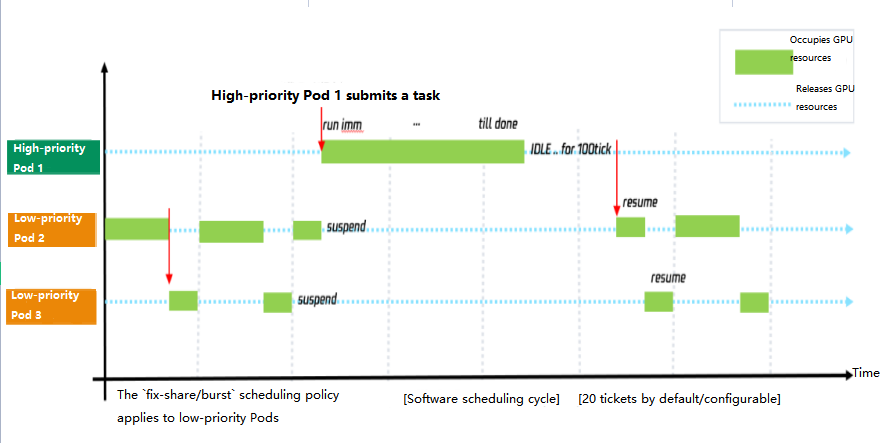
First, the qGPU driver perceives the requirements of high-priority Pods for GPU computing power and provides all computing power to them within one millisecond after they submit computing tasks. When high-priority Pods have no running tasks, the driver will release the occupied computing power after 100 milliseconds and allocate it to offline Pods.
Second, the qGPU driver supports suspending and resuming computing tasks. When a high-priority Pod has a running computing task, the low-priority Pod that occupies GPU computing power will be suspended immediately to release the computing power. When the task of the high-priority Pod ends, the low-priority Pod will be woken up to resume the computing task from where it ends. The sequence diagram of computing tasks at different priorities is as shown below:
Scheduling policy
On a general qGPU node, you can set the policy for scheduling Pods on the same card. In the online/offline hybrid deployment feature, the policy affects only the scheduling of low-priority Pods.
Low-priority Pods
When high-priority Pods are sleeping and low-priority Pods are running, low-priority Pods are scheduled based on the policy. When high-priority Pods use GPU computing power, all low-priority ones will be suspended immediately until the high-priority task ends, after which low-priority tasks resume based on the policy.
High-priority Pods
When high-priority Pods have computing tasks, they preempt the GPU computing power immediately. High-priority Pods always preempt resources from low-priority Pods, and high-priority Pods compete for GPU computing power with each other, both of which are not subject to a specific policy.