Public clouds are leased instead of purchased services with complete technical support and assurance, greatly contributing to business stability, scalability, and convenience. But more work needs to be done to reduce costs and improve efficiency, for example, adapting to application development, architecture design, management and Ops, and reasonable use in the cloud. According to the Kubernetes Standards for Cost Reduction and Efficiency Enhancement | Analysis of Containerized Computing Resource Utilization Rate, resource utilization is improved after IDC cloud migration, but not that much; the average utilization of containerized resources is only 13%, indicating a long and uphill way towards improvement.
This article details:
1. The reason for low CPU and memory utilization in Kubernetes clusters
2. TKE productized methods for easily improving resource utilization
Resource Waste Scenarios
To figure out why utilization is low, let's look at a few cases of resource use:
Scenarios 1: Over 50% of reserved resources are wasted
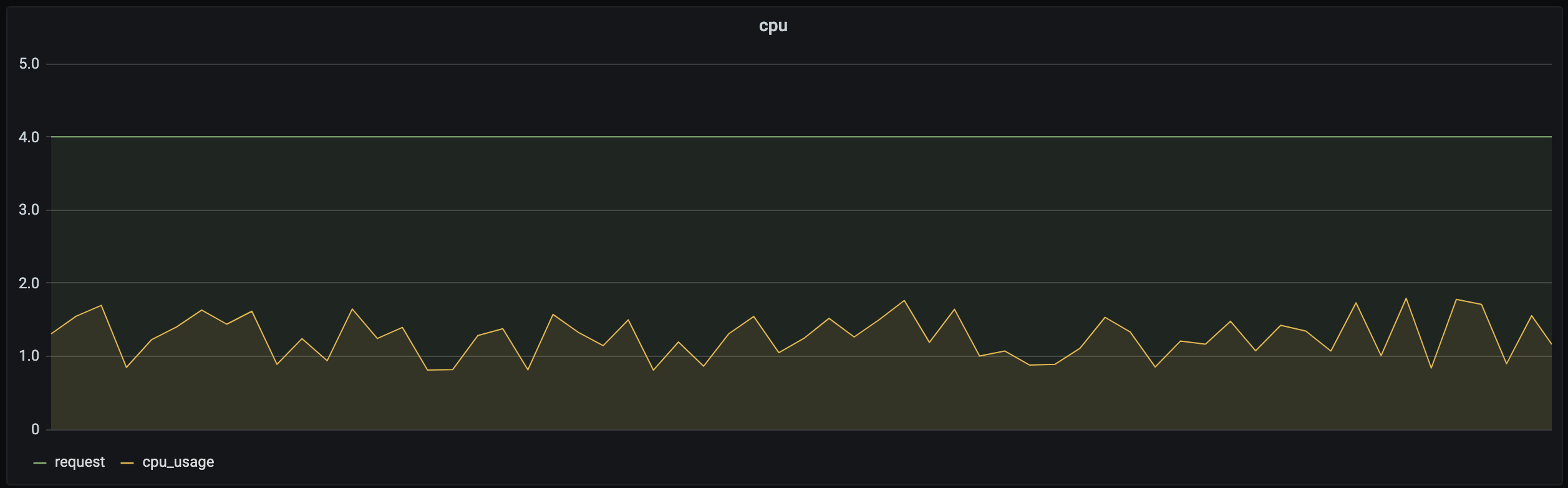
The Request field in Kubernetes manages the CPU and memory reservation mechanism, which reserves certain resources in one container from being used by another. For more information, see Resource Management for Pods and Containers. If Request is set to a small value, resources may fail to accommodate the business, especially when the load becomes high. Therefore, users tend to set Request to a very high value to ensure the service reliability. However, the business load is not that high most of the time. Taking CPU as an example, the following figure shows the relationship between the resource reservation (request) and actual usage (cpu_usage) of a container in a real-world business scenario:
As you can see, resource reservation is way more than the actual usage, and the excessive part cannot be used by other loads. Obviously, setting Request to a very high value leads to great waste. In response, you need to set a proper value and limit infinite business requests as needed, so that resources will not be occupied overly by certain businesses. You can refer to ResourceQuota and LimitRange discussed later. In addition, TKE will launch a smart request recommendation product to help you narrow the gap between Request and Usage, effectively improving resource utilization while guaranteeing business stability.
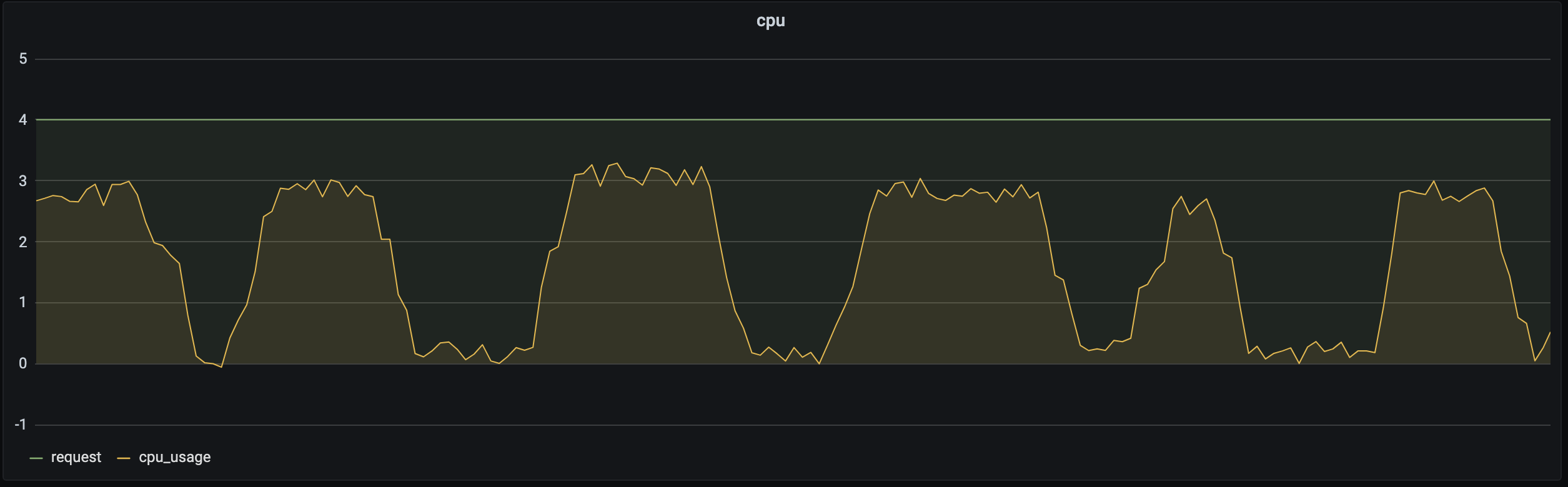
Scenario 2: Business resource utilization sees an obvious change pattern, and resource waste is serious during off-peak hours, which usually last longer than peak hours
Most businesses see an obvious change pattern in resource utilization. For example, a bus system usually has a high load during the day and a low load at night, and a game often starts to experience a traffic surge on Friday night, which drops on Sunday night.
As you can see, the same business requests different amounts of resources during different time periods. If Request is set to a fixed value, utilization will be low when the load is low. The solution is to dynamically adjust the number of replicas to sustain different loads. For more information, see HPA, HPC, and CA discussed later.
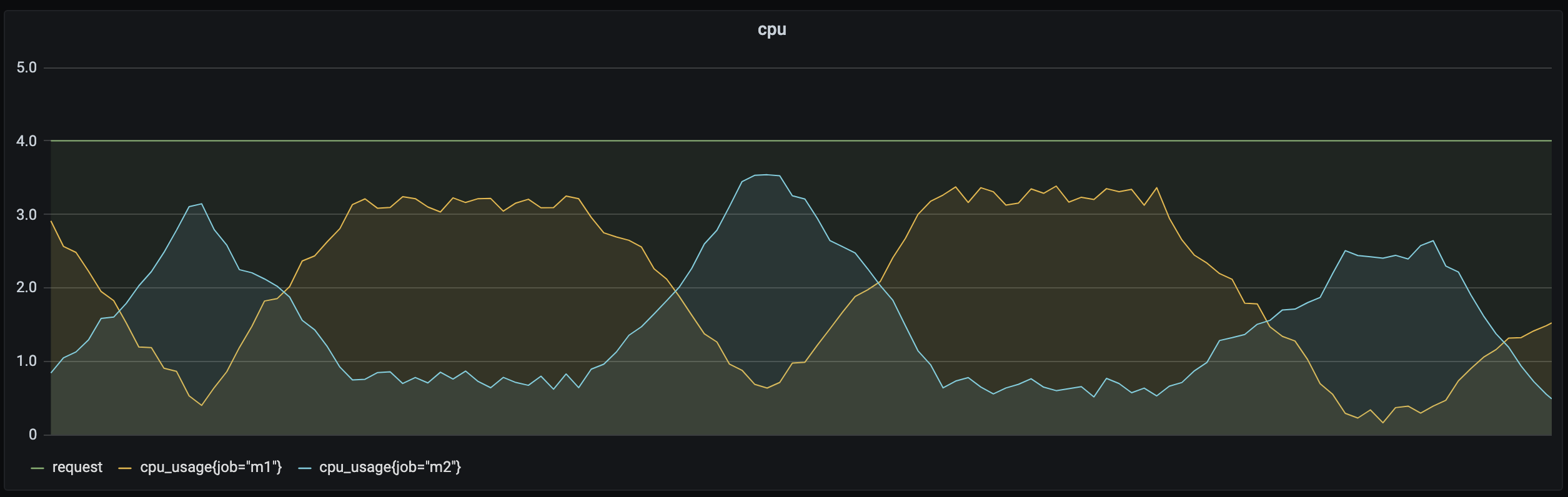
Scenario 3: Resource utilization differs greatly by business type
Online businesses usually have a high load during the day and require a low latency, so they must be scheduled and run first. In contrast, offline businesses generally have low requirements for the operating time period and latency and can run during off-peak hours of online business loads. In addition, some businesses are computing-intensive and consume a lot of CPU resources, while others are memory-intensive and consume a lot of memory resources.
As shown above, online/offline hybrid deployment helps dynamically schedule offline and online businesses in different time periods to improve resource utilization. For computing-intensive and memory-intensive businesses, affinity scheduling can be used to find the right node. For detailed directions, see online/offline hybrid deployment and affinity scheduling discussed later.
Improving Resource Utilization in Kubernetes
TKE has productized a series of tools based on a large number of actual businesses, helping you easily and effectively improve resource utilization. There are two ways: 1. manual resource allocation and limitation based on Kubernetes native capabilities; 2. automatic solution based on business characteristics.
1. Resource allocation and limitation
Imagine that you are a cluster administrator and your cluster is shared by four business departments. You need to ensure business stability while allowing for on-demand use of resources. In order to improve the overall utilization, it is necessary to limit the upper threshold of resources used by each business and prevent excess usage using some default values.
Ideally, Request and Limit values are set as needed. Here, Request is resource occupation, indicating the minimum amount of resources available for a container; Limit is resource limit, indicating the maximum amount of resources available for a container. This contributes to healthier container running and higher resource utilization, despite the fact that Request and Limit are often left unspecified. In the case of cluster sharing by teams/projects, Request and Limit tend to be set to high values to ensure stability. When you create a load in the TKE console, the following default values will be set for all containers, which are based on actual business analysis and estimation and may deviate from real-world requirements.
Resource
Request
Limit
CPU (core)
0.25
0.5
Memory (MiB)
256
1,024
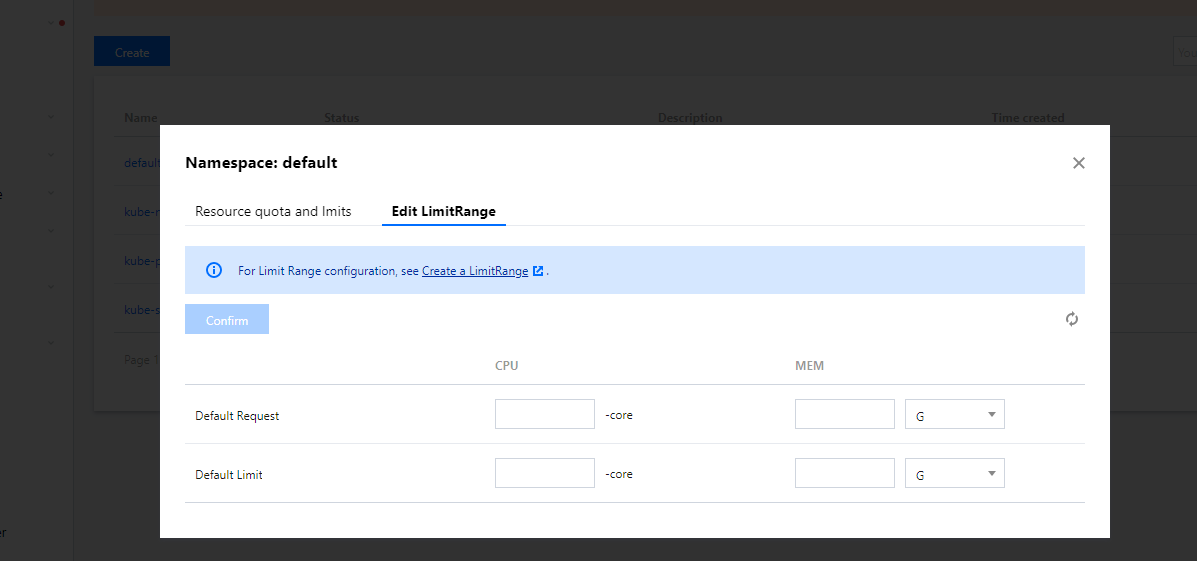
To fine-tune your resource allocation and management, you can set namespace-level "resource quota" and "limit range" on TKE.
`ResourceQuota` for resource allocation
Use "LimitRange" for resource limitation
If your cluster has four businesses, you can use the namespace and ResourceQuota to isolate them and limit resources.
ResourceQuota is used to set a quota on resources in a namespace, which is an isolated partition in a Kubernetes cluster. A cluster usually contains multiple namespaces to house different businesses. You can set different ResourceQuota values for different namespaces to limit the cluster resource usage by a namespace, thus implementing preallocation and limitation. ResourceQuota applies to the following. For more information, see Resource Quotas.
1. Computing resources: Sum of "request" and "limit" of CPU and memory for all containers
2. Storage resources: Sum of storage requests of all PVCs.
3. Number of objects: Total number of resource objects such as PVC/Service/Configmap/Deployment
ResourceQuota use cases
Assign different namespaces to different projects/teams/businesses and set resource quotas for each namespace for allocation.
Set an upper limit on the amount of resources used by a namespace to improve cluster stability and prevent excessive preemption and consumption of resources by a single namespace.
ResourceQuota in TKE
TKE has productized ResourceQuota. You can directly use it in the console to limit the resource usage of a namespace. For detailed directions, see Namespace.
What if Request and Limit are left unspecified or set to high values? If you are the admin, you may set different default values and ranges for different businesses to limit excessive resource preemption by businesses while facilitating creation.
Unlike ResourceQuota, which limits the overall resource usage of a namespace, LimitRange applies to a single container in a namespace. It can prevent creating containers that request too many or too few resources in a namespace and address the situation where Request and Limit are left unspecified. LimitRange applies to the following. For more information, see the Kubernetes official documentation Resource Quotas.
1. Computing resources: sets the range of CPU and memory usage for all containers.
2. Storage resources: the range of storage that can be requested for all PVCs.
3. Ratio setting: controls the ratio between "request" and "limit" of a resource.
4. Default: sets a default "request"/"limit" value for all containers. If a container does not specify "request" and "limit" for its memory, default values will be specified.
LimitRange use cases
1. Set the default value for resource usage to prevent it from being left unspecified and prevent important Pods from being drained by QoS.
2. Different businesses generally run in different namespaces and have different levels of resource utilization. Setting Request and Limit by namespace can improve resource utilization.
3. Limit the upper and lower thresholds of resource usage by a container and limit its request for too many resources while ensuring its normal operation.
LimitRange in TKE
TKE has productized LimitRange. You can directly manage it by namespace in the console. For detailed directions, see Namespace. For more information, see Limit Ranges.
2. Automatic improvement of resource utilization
ResourceQuota and LimitRange for resource allocation and limitation respectively rely on experience and manual operations, mainly addressing unreasonable resource requests and allocation. This section describes how to improve resource utilization through automated dynamic adjustments from the perspectives of elastic scaling, scheduling, and online/offline hybrid deployment.
2.1 Elastic scaling
HPA for elastic scaling by metric
HPC for scheduled scaling
CA for automatic adjustment of the number of nodes
In the second resource waste scenario, if your business goes through peak and off-peak hours, a fixed resource "request" value is bound to cause resource waste during off-peak hours. In this case, you can consider automatically increasing and decreasing the number of replicas of the business load during peak and off-peak hours respectively to enhance the overall utilization.
Horizontal Pod Autoscaler (HPA) can automatically increase and decrease the number of Pod replicas in Deployment and StatefulSet based on metrics such as CPU and memory utilization to stabilize workloads and achieve truly on-demand usage.
HPA use cases
1. Traffic bursts: if traffic becomes heavy suddenly, the number of Pods is automatically increased in time at overload.
2. Automatic scaling in: if traffic is light, the number of Pods is automatically decreased to avoid waste at underload.
HPA in TKE
TKE supports many metrics for elastic scaling based on the custom metrics API, covering CPU, memory, disk, network, and GPU in most HPA scenarios. For more information on the list, see HPA Metrics. In complex scenarios such as automatic scaling based on the QPS per replica, the prometheus-adapter can be installed. For detailed directions, see Using Custom Metrics for Auto Scaling in TKE.
Suppose you are planning 11/11 shopping spree promotions for your business on an e-commerce platform. You may consider using HPA for auto-scaling. However, HPA needs to monitor metrics first before reacting, which means it may not be fast enough to scale out and bear heavy traffic in time. If you have an expected traffic surge, consider scaling out replicas in advance.
Horizontal Pod Cronscaler (HPC) is a proprietary component of TKE, designed to control the number of replicas on schedule to scale and trigger the impact of insufficient resources during dynamic expansion in advance. Compared with CronHPA, HPC supports:
1. Combination with HPA: enables and disables HPA on schedule to make your business more resilient during peak hours.
2. Exceptional date setting: sets exceptional dates to reduce manual adjustment of HPC, as business traffic is unlikely to remain regular all the time.
3. Single execution: it makes you more flexible in promotion use cases, as previous CronHPA executions are permanent, similar to Cronjob.
HPC use cases
In the case of gaming services, the number of players skyrockets from Friday night to Sunday night. You can scale out the game server before Friday night and scale it in to the original size after Sunday night to ensure a better experience. If HPA is used, services may suffer because scaling out is not fast enough.
HPC in TKE
TKE has productized HPC that uses the crontab syntax format, but you need to install it on the Add-On Management page in advance. For operation details, see Automatic Scaling Basic Operations.
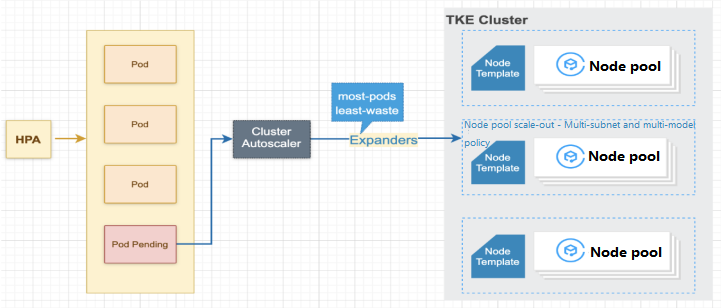
Both HPA and HPC mentioned above increase and decrease the number of replicas automatically at the business load level to adapt to traffic fluctuations and improve resource utilization. However, at the cluster level, the total amount of resources is fixed, and HPA and HPC only allow the cluster to have more spare resources. Is there a way to reclaim some resources during idle hours and expand the cluster during busy hours? Such cluster-level elastic scaling is quite cost-efficient, as the overall resource usage of a cluster determines the billing cost.
Cluster Autoscaler (CA) is used to automatically adjust the number of cluster nodes to truly achieve improved resource utilization and save user costs. It is the key to cost reduction and efficiency enhancement.
CA use cases
1. Scale out the right nodes during the peak based on the surge of business load.
2. Release excess nodes during the trough based on resource availability.
CA in TKE
CA in TKE is provided in the form of node pools. We recommend you use CA together with HPA, as the former performs resource-layer (node-layer) scaling, while the latter application-layer scaling. When the overall resources are insufficient after an HPA scale-out, Pods will be pending, and CA will expand the node pool to increase the overall resource volume in the cluster.
For more information on parameter configuration methods and use cases, see here or Node Pool Overview.
2.2 Scheduling
The Kubernetes scheduling mechanism is a native resource allocation mechanism which is efficient and graceful. Its core feature is to find the right node for each Pod. In TKE scenarios, the scheduling mechanism contributes to the transition from application-layer to resource-layer elastic scaling. A reasonable scheduling policy can be configured based on business characteristics by properly leveraging Kubernetes scheduling capabilities to effectively enhance resource utilization in clusters.
Node affinity
Dynamic Scheduler
If Kubernetes' scheduler accidentally scheduled a CPU-intensive business instance to a memory-intensive node, all the CPU of the node will be taken up, but its memory will be barely used, resulting in a serious waste of resources. In this case, you can flag such a node as a CPU-intensive node and flag a business load during creation to indicate that it is a CPU-intensive load. Kubernetes' scheduler will then schedule the load to a CPU-intensive node, a way of finding the most suitable node to effectively improve resource utilization.
When creating Pods, you can set node affinity to specify nodes to which Pods will be scheduled (these nodes are specified with Kubernetes labels).
Node affinity use cases
Node affinity is ideal for scenarios where there are workloads with different resource requirements running simultaneously in a cluster. For example, Tencent Cloud's CVM nodes can be CPU-intensive or memory-intensive. If certain businesses require much higher CPU usage than memory usage, using common CVMs will inevitably cause a huge waste of memory. In this case, you can add a batch of CPU-intensive CVMs to the cluster and schedule CPU-consuming Pods to these CVMs, so as to improve the overall utilization. Similarly, you can manage heterogeneous nodes (such as GPUs) in the cluster, specify the amount of GPU resources needed in the workloads, and have the scheduling mechanism find the right nodes to run these workloads.
Node affinity in TKE
TKE provides an identical method to use node affinity as native Kubernetes. You can use this feature in the console or by configuring a YAML file. For detailed directions, see Proper Resource Allocation.
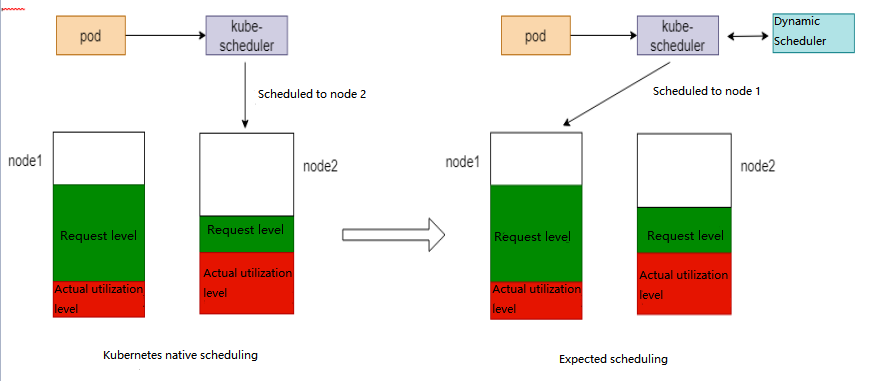
The native Kubernetes scheduling policy, such as the default LeastRequestedPriority policy, tends to schedule Pods to nodes with more resources remaining. However, this kind of resource allocation is static and "request" does not represent the real resource usage, so there must be some level of waste. If the scheduler can schedule resources based on the actual resource utilization of nodes, it will avoid resource waste to some extent.
The proprietary Dynamic Scheduler of TKE is a solution, which works as shown below:
Dynamic scheduler use cases
In addition to reducing resource waste, the dynamic scheduler can well mitigate scheduling hotspots in a cluster.
1. The dynamic scheduler counts the number of Pods that have been scheduled to a node over time to avoid scheduling too many Pods to the same node.
2. The dynamic scheduler supports setting a load threshold for a node to filter out nodes that exceed the threshold during scheduling.
Dynamic Scheduler in TKE
You can install and use the Dynamic Scheduler in an extended add-on:
For more information on the Dynamic Scheduler guide, see here and DynamicScheduler.
2.3 Online/Offline hybrid business deployment
If you have both online web businesses and offline computing businesses, you can use TKE's online/offline hybrid deployment technology to dynamically schedule and run businesses to improve resource utilization.
In the traditional architecture, big data and online businesses are independent and deployed in different resource clusters. Generally, big data businesses are for offline computing and experience peak hours during nights, during which online businesses are barely loaded. Leveraging complete isolation capabilities of containers (involving CPU, memory, disk I/O, and network I/O) and strong orchestration and scheduling capabilities of Kubernetes, cloud-native technologies implement the hybrid deployment of online and offline businesses to fully utilize resources during idle hours of online businesses.
Use cases of online/offline hybrid deployment
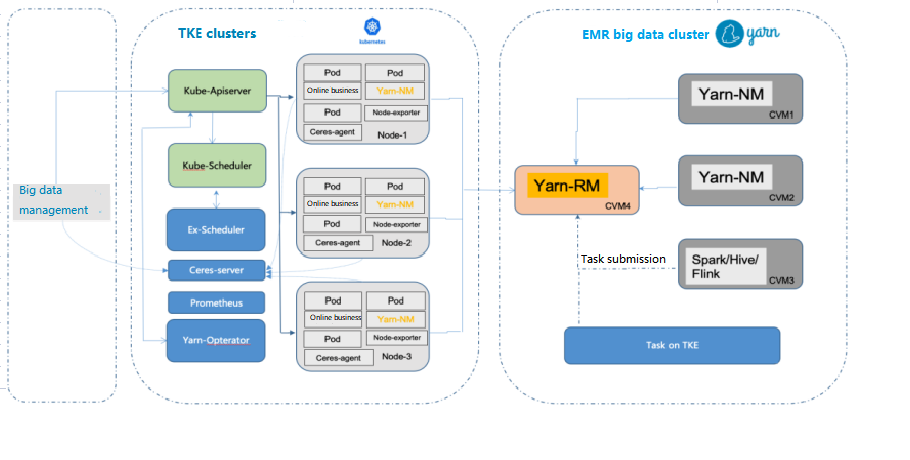
In the Hadoop architecture, offline and online jobs are in different clusters. Online and streaming jobs experience obvious load fluctuations, which means a lot of resources will be idle during off-peak hours, leading to great waste and higher costs. In clusters with online/offline hybrid deployment, offline tasks are dynamically scheduled to online clusters during off-peak hours, significantly improving resource utilization. Currently, Hadoop YARN can only statically allocate resources based on the static resource status reported by NodeManager, making it unable to well support hybrid deployment.
Online/Offline hybrid deployment in TKE
Online businesses experience obvious and regular load fluctuations, with a low resource utilization at night. In this case, the big data management platform delivers resource creation requests to Kubernetes clusters to increase the computing power of the big data application. For more information, see here.
How to Balance Resource Utilization and Stability
Besides costs, system stability is another metric that weighs heavily in enterprise Ops. It's challenging to balance the two. On the one hand, the higher the resource utilization, the better for cost reduction; on the other hand, a too high resource utilization may cause overload and thereby OOM errors or CPU jitters.
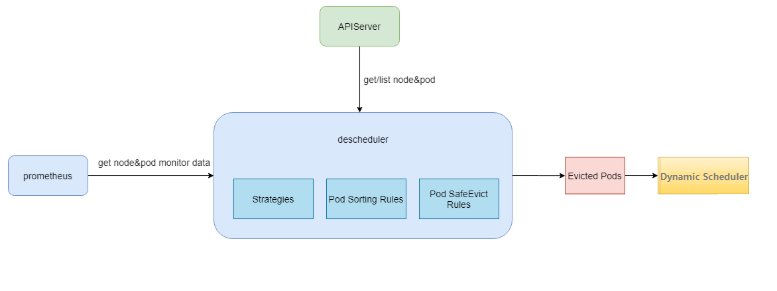
To help enterprises get rid of the dilemma, TKE provides the DeScheduler to keep the cluster load under control. It is responsible for protecting nodes with risky loads and gracefully draining businesses from them. The relationship between the DeScheduler and the Dynamic Scheduler is as shown below:
DeScheduler in TKE
You can install and use the DeScheduler in an extended add-on. For detailed directions, see DeScheduler.
For more information on the DeScheduler guide, see here.