In many TKE scenarios, such as Kubernetes version upgrade and kernel version upgrade, you must remove the node and then add it back. This document describes the process of removing and re-adding a node in detail. This operation can be divided into the following steps:
1. Drain the Pods running on the node.
2. Remove the node from the cluster, and then re-add it to the cluster. This node will reinstall the system.
3. Remove the cordon.
Notes
If multiple nodes on a single cluster all need to be removed and added back, it is recommended that you do so node by node. That is, complete the removal and addition of a single node and verify that the service is normal, and then remove the next node and add it back, completing multiple nodes successively.
If you need to do this for multiple clusters under the same account, we recommend that the operation be executed in batches. After the operation has been completed on each cluster, verify whether the cluster status is normal.
Directions
Step 1: drain Pods
Before performing the removal and re-addition of a node in a cluster, you must first drain the Pods on the node to be removed to have them operate on a different node. The draining process involves deleting the Pods on the node one by one, and then reconstruct them on another node.
Principles of draining
To streamline node maintenance operations, Kubernetes introduced the drain command. The use principles are as follows:
For versions after Kubernetes 1.4, the drain operation is to first cordon the node and then delete all the Pods on the node. If this Pod is managed by a controller such as Deployment, the controller will re-construct the Pod when it detects that the number of Pod replicas has decreased, and will schedule them to other nodes that meet the conditions. If this Pod is a bare Pod that is not managed by a controller, it will not be re-constructed after it is drained.
This process involves first deleting, and then re-creation, and is not a rolling update. Therefore, in the update process, some requests for drained services may fail. If all the related Pods of the drained service are on the drained node, the service may become completely unavailable.
To avoid this situation, Kubernetes versions 1.4 and later introduced PodDisruptionBudget (PDB). You only need to select a business (a group of Pods) in the PDB policy file, to declare the minimum number of replicas that this business can tolerate. Now when you execute the drain operation, the Pod is no longer deleted directly, but instead whether it meets the PDB policy is checked through evict api. The Pods will only be deleted if the PDB policy is satisfied, protecting business availability. Note that the impact of the drain operation on businesses can only be controlled if PDB is correctly configured.
Checking before draining
The draining process involves reconstructing Pods, which may affect services in the cluster. Therefore, it is recommended that you perform the following checks before performing draining:
1. Check whether the remaining nodes in the cluster have sufficient resources to run the Pods on the node to be drained.You can check the resource allocation of the nodes in the TKE console. On the Cluster List page, select the target cluster ID > Node Management > Node, and check the Assigned/Total Resources on the Node List page.
If the remaining resources of the nodes are insufficient, it is recommended that you add new nodes to the cluster to prevent the drained Pod from being unable to run and, as a result, affecting the service.
2. Check whether active drainage protection, PodDisruptionBudget (PDB), is configured in the cluster.Active drainage protection interrupts the execution of drainage operations. It is recommended that you first delete the active drainage protection PDB.
3. Check whether all the Pods of a single service are on the node to be drained.If all the Pods of a single service are located on the same node, draining the Pods will make the entire service unavailable. Please determine whether the service needs all Pods to be located on the same node.
If not, it is recommended that you add anti-affinity scheduling.
If so, it is recommended that you perform the operation during periods of low or no traffic.
4. Check if the service uses a local disk (hostpath).If the service uses the hostpath volume method, when the Pod is scheduled to another node, the data will be lost which may affect the business. If the data is important, back it up before draining.
Note:
Currently, kubelet’s image pull policy is serial. If a large number of Pods is scheduled to the same node in a short period of time, the Pod launch time may be longer.
Details
Currently, there are two ways to complete drainage for TKE clusters:
Drain in TKE Console
Use the kubectl drain Command to Drain
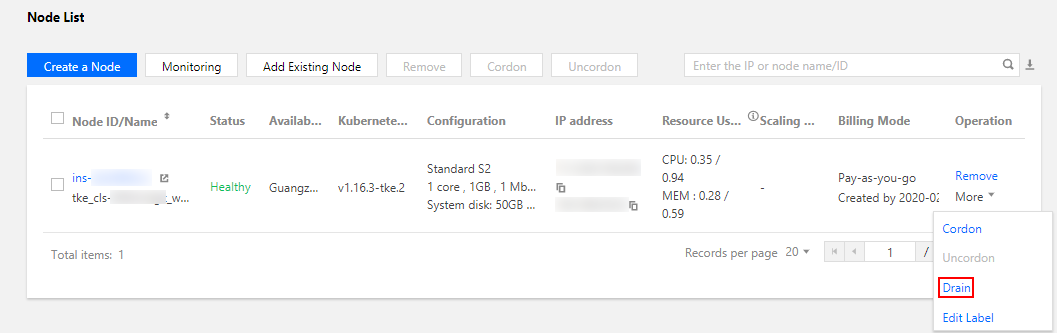
1. On the cluster list page, click the target cluster ID.
2. On the cluster details page, select Node Management > Node.
3. On the Node page, click Drain in the Operation column of the target node.
4. In the pop-up window, confirm the node information and click OK.
2. Execute the following command to drain the Pods on this node.
kubectl drain node<node-name>
Step 2: remove the node
When the Pods running on a node are drained, this node is cordoned.
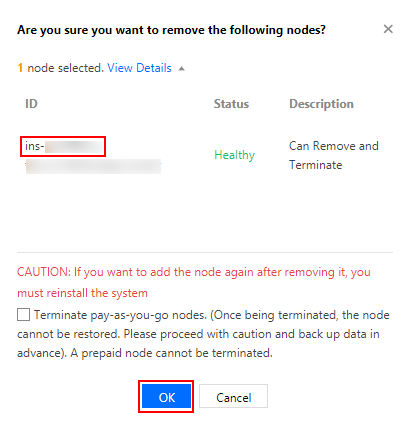
1. On the Node List page, click Remove in the Operation column of the target node.
2. In the pop-up window, deselect Terminate pay-as-you-go nodes and click OK to remove the node from the cluster.
Note:
Note the node ID to be used for re-adding the node to the cluster.
If the node is pay-as-you-go, make sure not to select Terminate pay-as-you-go nodes. Terminated nodes cannot be restored.
Step 3: add the node back to the cluster
1. On the Node List page, click Add Existing Node on the top of the page.
2. On the Add Existing Node page, enter the recorded node ID and click
.
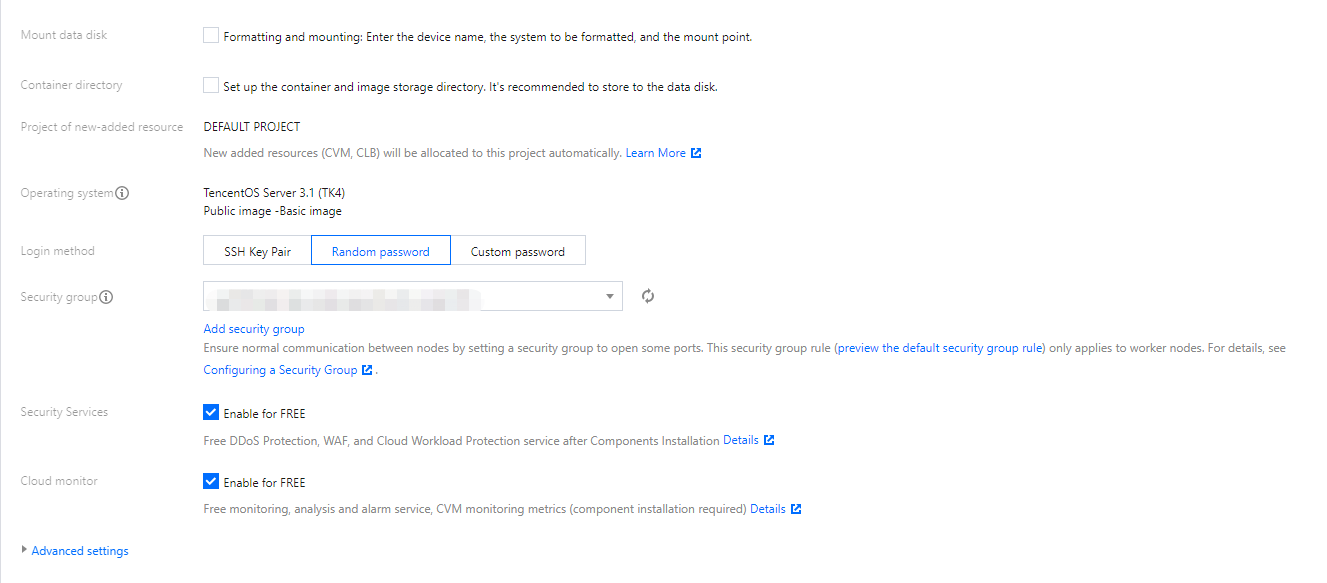
3. In the search result list, select the target node and set CVM and other parameters as needed.
Note:
Mount Data Disk and Container Directory are not selected by default.
If you need to store the container and image on the data disk, select Mount Data disk. When Mount Data Disk* is selected, formatted system disks of ext3, ext4 or XFS file systems will be mounted directly. Data disks of other file systems or unformatted data disks will be automatically formatted as ext4 and mounted.
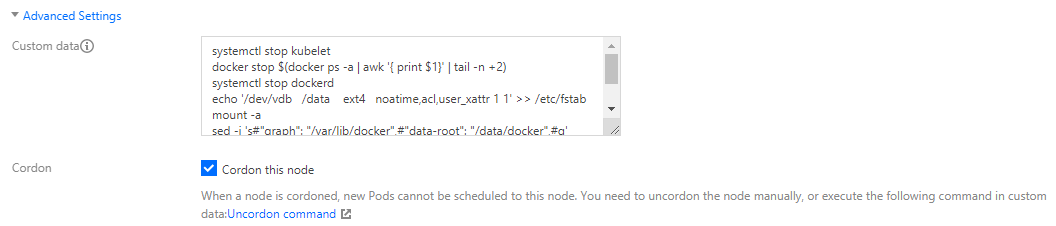
If you need to keep the data on the data disk and mount the data disk without formatting it, perform the steps below:
1. On the CVM Configuration page, do not select Mount Data Disk.
2. Open Advanced Settings. In the Custom Data area, enter the following node initialization script and select Cordon this node.