Support only native nodes. Native nodes, equipped with FinOps concepts and paired with qGPU, can substantially improve the utilization of GPU/CPU resources.
Supported GPU Card Architectures
Support Volta (such as V100), Turing (such as T4), Ampere (such as A100, A10), L40 (Pnv5i), L40s (Pnv5), Pnv5b and Pnv6 cards.
Supported Driver Versions
The nvidia driver minor version (end version number, e.g., 450.102.04, where the minor version corresponds to 04) needs to satisfy the following conditions:
450: <= 450.102.04
470: <= 470.161.03
515: <= 515.65.01
525: <= 525.89.02
Shared Granularity
Each qGPU is assigned a minimum of 1G of vRAM, with a precision unit of 1G. Computing capacity is allocated at a minimum of 5 (representing 5% of one card), up to 100 (a whole card), with a precision unit of 5 (i.e., 5, 10, 15, 20...100).
Complete Card Allocation
Nodes with qGPU capability enabled can allocate whole cards in the manner of tke.cloud.tencent.com/qgpu-core: 100 | 200 | ... (N * 100, N is the number of whole cards). It is recommended to differentiate the NVIDIA allocation method or convert to qGPU usage through TKE's node pool capability.
Quantity Limits
Up to 16 qGPU devices can be created on one GPU. It is recommended to determine the number of qGPU shareable per GPU card based on the size of the vRAM requested by the container deployment.
Note:
If you have upgraded the Kubernetes Master version of your TKE cluster, please pay attention to the following points:
For a managed cluster, you do not need to reconsider configuring this plugin.
In case of a self-deployed cluster (with a self-maintained Master), an upgrade to the Master version might reset the configuration of all components on the Master. This could potentially affect the configuration of the qGPU-scheduler plugin as a Scheduler Extender. Therefore, it is required to uninstall the qGPU plugin first, and then reinstall it.
Kubernetes objects deployed in a cluster
Kubernetes Object Name
Type
Requested Resource
Namespace
qgpu-manager
DaemonSet
Each GPU node with one Memory: 300 M, CPU: 0.2
kube-system
qgpu-manager
ClusterRole
-
-
qgpu-manager
ServiceAccount
-
kube-system
qgpu-manager
ClusterRoleBinding
-
kube-system
qgpu-scheduler
Deployment
A single replica Memory: 800 M, CPU: 1
kube-system
qgpu-scheduler
ClusterRole
-
-
qgpu-scheduler
ClusterRoleBinding
-
kube-system
qgpu-scheduler
ServiceAccount
-
kube-system
qgpu-scheduler
Service
-
kube-system
qGPU Permission
Note:
The Permission Scenarios section only lists the permissions related to the core features of the components, for a complete permission list, please refer to the Permission Definition.
Permission Description
The permission of this component is the minimal dependency required for the current feature to operate.
It is required to install qgpu ko kernel files and create, manage, and delete qgpu device, thus the initiation of the privileged level container is required.
Permission Scenarios
Feature
Involved Object
Involved Operation Permission
Track the status changes of a pod, access pod information, and clean up resources such as qgpu devices when a pod is deleted.
pods
get/list/watch
Monitor the status changes of a node, access node information, and add labels to nodes based on gpu card driver and version information as well as qgpu version information.
nodes
get/list/watch/update
The qgpu-scheduler is an extender-based scheduler specifically developed for qgpu resources, based on the Kubernetes scheduler extender mechanism. The permissions it requires align with those of other community scheduler components (such as Volcano), including tracking and access to pod information, updating scheduling results to pod labels and annotations, tracking and access to node information, accessing configuration via the configmap, and creating scheduling events.
pods
get/list/update/patch
nodes
get/list/watch
configmaps
get/list/watch
events
create/patch
gpu.elasticgpu.io is qgpu's proprietary CRD resource ( this feature has been deprecated, but to be compatible with earlier versions, the resource definition must be retained) for recording GPU resource information, managed by qgpu-manager and qgpu-scheduler. It requires permissions for a full range of operations, including creation, deletion, modification, and queries.
2. In the Cluster list, click the desired Cluster ID to access its detailed page.
3. Select Component Management from the left menu bar, and click Create on the Component Management page.
4. Select the QGPU (GPU Isolation Component) on the Create Component Management page.
5. Click Parameter Configuration, and set the scheduling policies of qgpu-scheduler.
Spread: Multiple Pods would be distributed across different nodes and GPU cards, prioritizing nodes with greater residual resources. It applies to high-availability scenarios to avoid placing replicas of the same application on the same device.
Binpack: Multiple Pods would primarily use the same node, making this suitable for scenarios aiming to increase GPU utilization.
6. Click Complete to create the component. Once installed, GPU resources need to be prepared for the cluster.
Step 2: Prepare GPU resources and activate qGPU sharing
1. In the Cluster list, click the desired Cluster ID to access its detailed page.
2. In Node Management > Worker Node, select the Node Pool tab, then click New.
3. Select Native Node, then click Create.
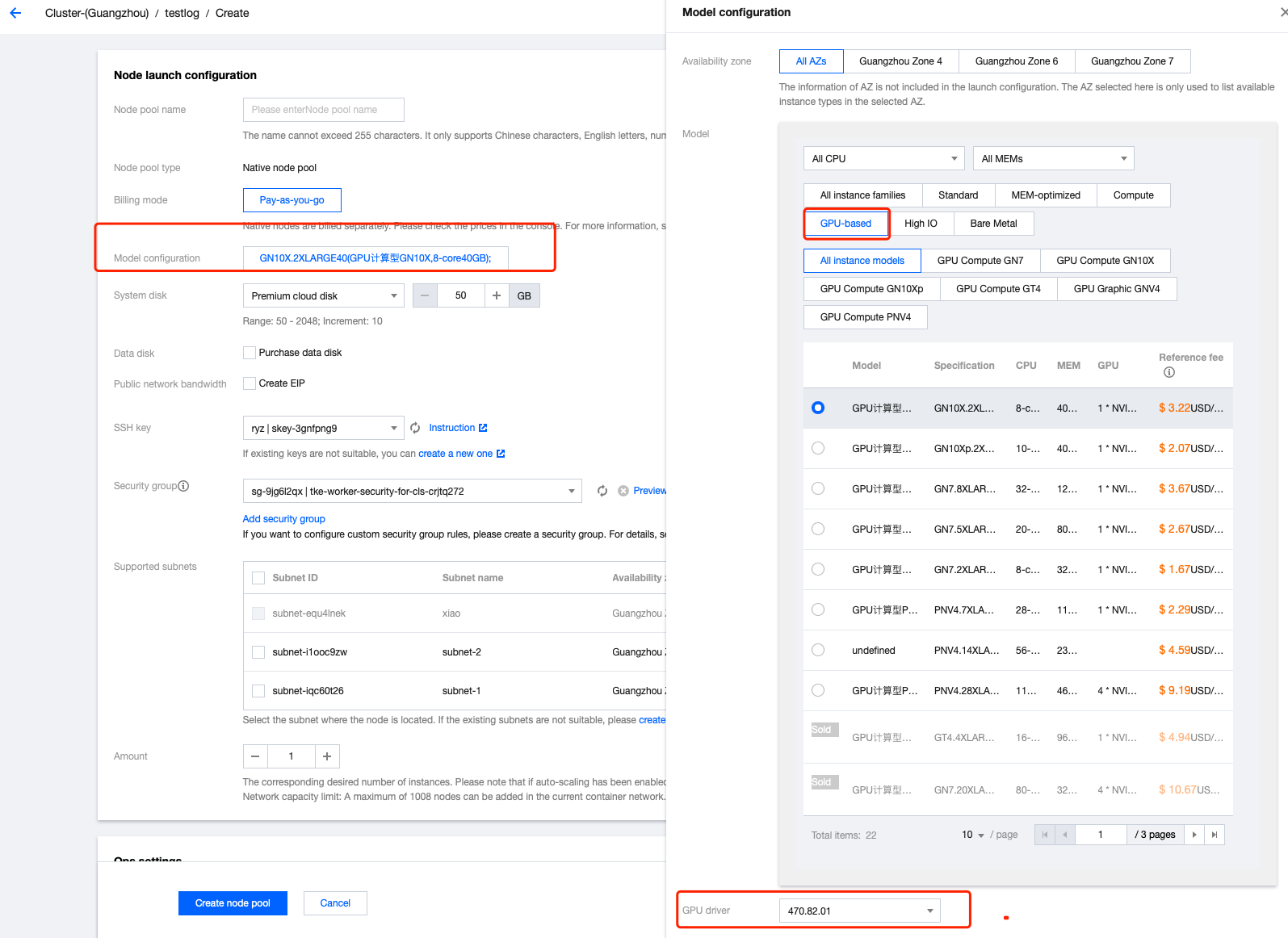
4. In the Create page, select the corresponding GPU model and choose the driver version supported by qgpu as shown below:
5. In Operation Feature Setting, click the switch on the right of qGPU Sharing. After the switch is enabled, all new GPU native nodes in the node pool will enable GPU sharing by default. You can control whether to enable isolation capability through Labels.
6. In Advanced Settings > Labels, set Labels via the advanced configuration of the node pool, designating qGPU isolation policies:
Label Value: fixed-share (The full name or abbreviation of the label value can be provided, more values are available in the table below)
Currently, qGPU supports the following isolation policies:
Label Value
Abbreviation
Name
Meaning
best-effort
(Default value)
be
Best Effort
Default value. The computing capacity for each Pod is limitless and can be used as long as there is remaining computing capacity on the card. If a total of N Pods are enabled, each Pod bearing a substantial workload, the result would eventually be a computing capacity of 1/N.
fixed-share
fs
Fixed Share
Each Pod is granted a fixed compute quota that cannot be exceeded, even if the GPU still possesses unused computing capacity.
burst-share
bs
Guaranteed Share with Burst
The scheduler ensures each Pod has a minimum compute quota but as long as the GPU has spare capacity, it may be used by a Pod. For instance, when the GPU has unused capacity (not assigned to other Pods), a Pod can use the computing capacity beyond its quota. Please note that when this portion of the unused capacity is reassigned, the Pod will revert to its computing quota.
7. Cli̇ck Create a node pool.
Step 3: Allocate shared GPU resources to the application
Setting the qGPU corresponding resources to containers can enable the Pod to use qGPU. You can assign GPU resources to your application via the console or YAML.
Note:
If the application requires to use the whole card resources, just fill in the card quantity; there is no need to fill in the vRAM (it will automatically use all the vRAM on the allocated GPU card).
If the application requires to use the decimal card resources (i.e., sharing the same card with other applications); it requires to fill in both the card quantity and the vRAM simultaneously.
Setting via the Console
Setting via YAML
1. Choose Workload in the left navigation bar of the cluster. Click Create on any workload object type page. This document takes Deployment as an example.
2. On the Create Deployment page, select Instance Container and fill in the GPU-related resources as shown below:
Setting related qGPU resources through YAML:
spec:
containers:
resources:
limits:
tke.cloud.tencent.com/qgpu-memory:"5"
tke.cloud.tencent.com/qgpu-core:"30"
requests:
tke.cloud.tencent.com/qgpu-memory:"5"
tke.cloud.tencent.com/qgpu-core:"30"
Where:
The resource values related to qGPU in the requests and limits must be consistent (According to the rules of K8S, the setting for qGPU in the requests can be omitted, in this case, the requests will be automatically set to the same value as the limits).
tke.cloud.tencent.com/qgpu-memory indicates the vRAM (Unit: G) requested by the container, allocated in integer values, decimal values are not supported.
tke.cloud.tencent.com/qgpu-core represents the computing capacity applied by the container. Each GPU card can provide 100% computing capacity, the setting of qgpu-core should be less than 100. If the setting value exceeds the remaining computing capacity ratio value, then the setting fails. After setting, the container can obtain a CPU card with n% computing capacity.