To help you efficiently manage nodes in a Kubernetes cluster, TKE introduced the concept of node pool. Basic node pool features allow you to conveniently and quickly create, manage, and terminate nodes and dynamically scale nodes in or out.
When a Pod in the cluster cannot be scheduled due to insufficient resources, scale-out will be triggered automatically, reducing labor costs.
When a scale-down condition such as node idleness is met, scale-down will be triggered automatically, which reduces the resource costs.
Product Architecture
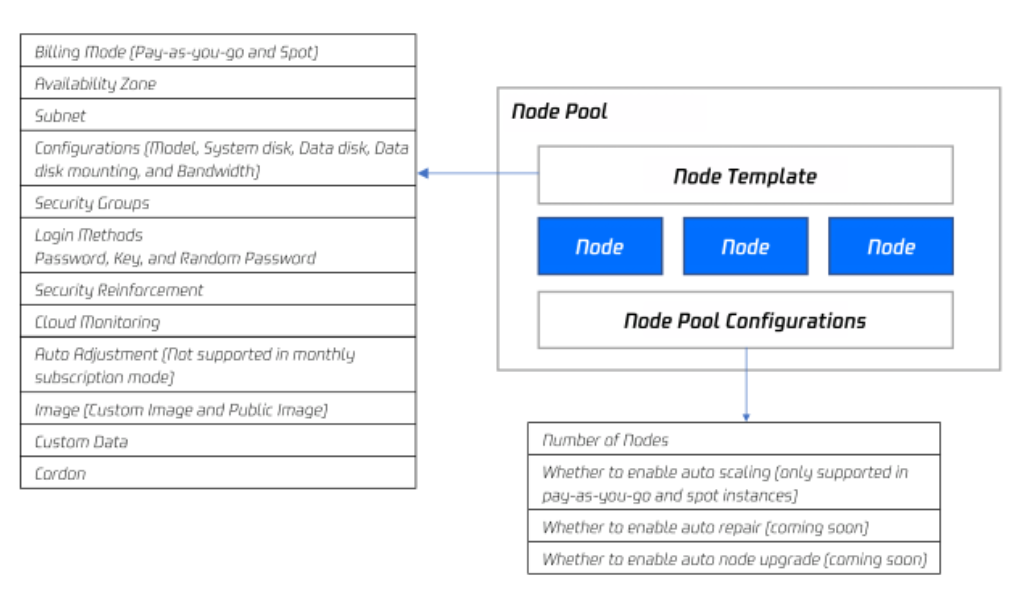
The overall architecture of a node pool is as follows:
Generally, all nodes in a node pool share the following attributes:
Node-level operating system
Billing type (currently pay-as-you-go and spot instances are supported)
CPU/memory/GPU
Launch parameters of Kubernetes components for nodes
Custom launch script for nodes
Kubernetes Label and Taints settings for nodes
In addition, TKE extends the following features for a node pool:
Supports managing node pool with CRD
Maximum number of Pods for each node in a specific node pool
Node-pool-level automatic repair and upgrade
Use Cases
When you need to use a large-scale cluster, we recommend that you use a node pool to manage nodes to improve the usability of the large-scale cluster. The following table describes multiple use cases for managing large-scale clusters and shows the effect of node pools in each use case.
Use Case
Effect
A cluster includes many heterogeneous nodes with different model configurations.
A node pool allows you to manage the nodes by groups in a unified manner.
A cluster needs to frequently scale nodes in and out.
A node pool improves OPS efficiency and reduces operating costs.
The scheduling rules for applications in a cluster are complex.
Node pool labels allow you to quickly specify service scheduling rules.
Routine maintenance is required for nodes in a cluster.
A node pool allows you to conveniently upgrade the Kubernetes version and the Docker version.
Concepts
TKE Auto Scaling is implemented based on Tencent Cloud Auto Scaling and the cluster-autoscaler of the Kubernetes community. The relevant concepts are described as follows:
CA: cluster-autoscaler, an open-source component of the community, is mainly responsible for the auto scaling of the cluster.
AS: Auto Scaling, the Tencent Cloud Auto Scaling service.
ASG: Auto Scaling Group, a specific scaling group (The node pool depends on the scaling group provided by the Auto Scaling service. A node pool corresponds to a scaling group. You only need to care about the node pool).
ASA: AS activity, a scaling activity.
ASC: AS config, the AS launch configuration, namely the node template.
Node Types in a Node Pool
To meet the requirements of different scenarios, the nodes in a node pool can be classified into the following two types:
Note:
It is not recommended to add existing nodes. If you do not have the permission to create nodes, you can add the existing nodes to scale out the cluster. However, some parameters of adding existing nodes may be inconsistent with the template of the node you defined, and the auto scaling cannot be performed.
Node Type
Node Source
Supporting Auto Scaling
Mode of Removal from Node Pool
Is Node Quantity Affected by Adjust Node Number
Nodes in the scaling group
Auto scale-out or manual adjustment of the node quantity
Yes
Auto scale-in or manual adjustment of the node quantity
Yes
Nodes outside the scaling group
Manually added to the node pool by users
No
Manually removed by users
No
How the Node Pool Auto Scaling Works
Please read how the node pool auto scaling works before using it.
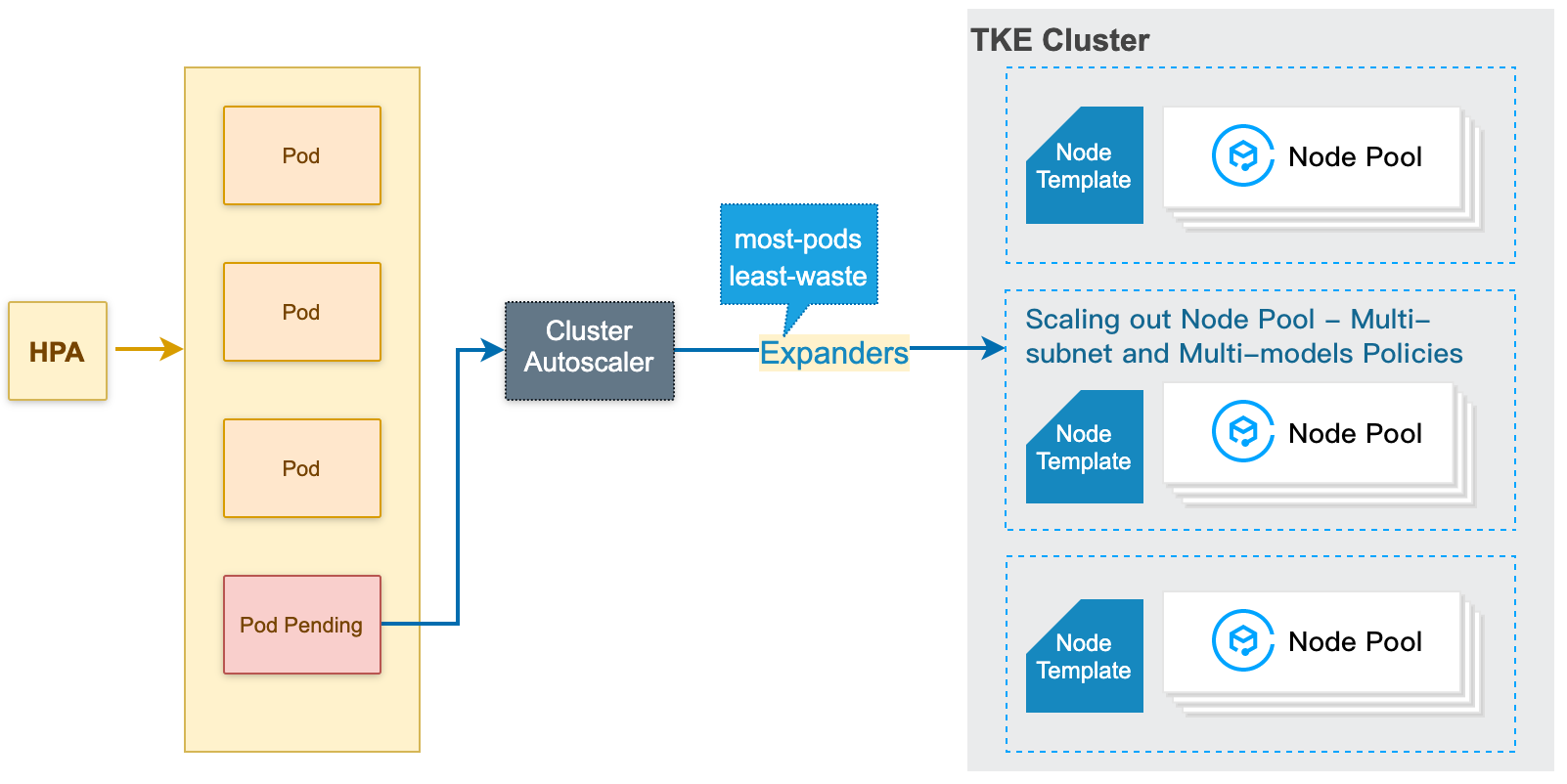
How the node pool auto scale-out works
1. When the resources in the cluster are insufficient (the computing/storage/network resources of the cluster cannot meet the Pod request/affinity rules), the CA (Cluster Autoscaler) will detect the pending Pods due to the scheduling failure.
2. CA makes scheduling judgments based on the node template of each node pool, and selects the appropriate node template.
3. If there are multiple suitable templates, that is, multiple node pools are available for scale-out, CA will call expanders to select the optimal template from the multiple templates and scale out the corresponding node pool.
4. The specified node pool will be scaled out (based on the multi-subnet and multi-model policy), and two retry policies (set during the creation of the node pool) are provided. When the scale-out fails, it will retry based on the configured retry policies.
Note
The scale-out of a specific node pool is performed based on the subnet you set when creating the node pool and the subsequent multi-model configuration. Generally, the multi-model policy shall prevail, and the next is the multi-zone/subnet policy.
For example, if you configure multiple models A, B, multiple subnets 1, 2, 3, the scale-out is performed based on A1, A2, A3, B1, B2, and B3 in sequence. If A1 is sold out, the scale-out performed based on A2 instead of B1.
The following figure shows how the node pool auto scale-out works:
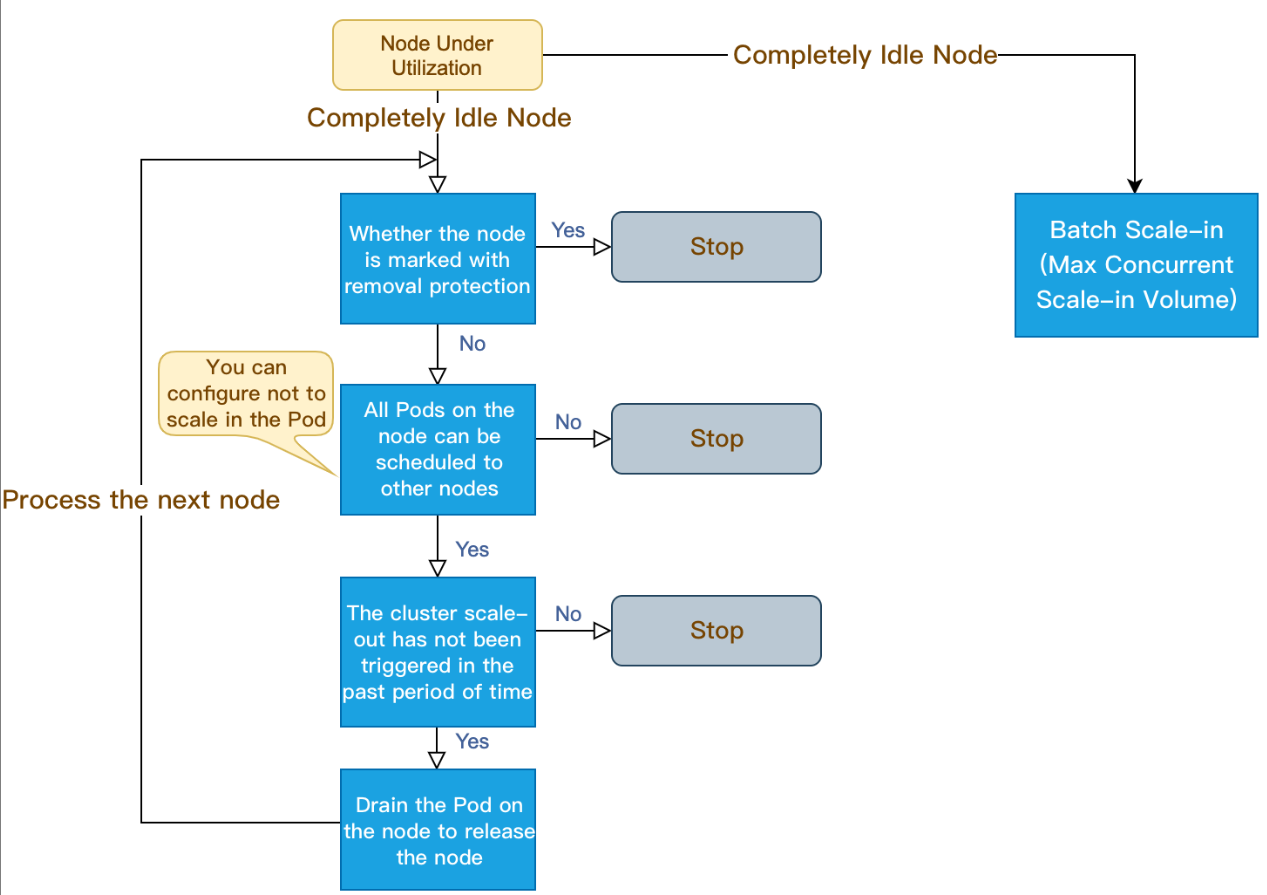
How the node pool auto scale-in works
1. Cluster Autoscaler (CA) detects that the allocation rate (value of Request, which takes the maximum value of CPU allocation rate and MEM allocation rate) is lower than the set node. When calculating the allocation rate, you can set the Daemonset type to not be included in the resources occupied by the Pod.
2. CA determines whether the scale-in can be triggered in the current cluster status. The following requirements must be met:
The node idle time is met (10 minutes by default).
The buffer time for cluster scale-out is met (10 minutes by default).
3. CA judges whether the node meets the scale-in conditions. You can set the nodes not be scaled in as needed (the nodes that meet the conditions will not be scaled in by CA).
Nodes with local storage
Nodes with Pods in kube-system namespace and not managed by DaemonSet
Note
The nodes not be scaled in only take effect in cluster level. If you need more fine-grained protection of nodes from being scaled in, you can use the removal protection feature.
4. CA drains the Pod on the node, and then releases/shuts down the node.
The completely idle nodes can be scaled in concurrently. (You can set the max concurrent scale-in volume.)
The non-completely idle nodes are scaled in one by one.
The following figure shows how the node pool auto scale-in works:
When you delete a node pool, you can select whether to terminate nodes in the node pool.
No matter whether the node is terminated or not, the node will not be retained in the cluster.
When you delete a node pool, if you select to terminate nodes, the nodes will not be retained. You can create new nodes later if required.
Enabling auto scaling for a node pool
After you enable auto scaling for a node pool, the number of nodes in the node pool is automatically adjusted according to the workload of the cluster.
Do not enable or disable auto scaling on the scaling group page in the console.
Disabling auto scaling for a node pool
After you disable auto scaling for a node pool, the number of nodes in the node pool is not automatically adjusted based on the workload of the cluster.
Adjusting the number of nodes in a node pool
You can directly adjust the number of nodes in a node pool.
If you decrease the number of nodes, the nodes in the scaling group are scaled in based on the node removal policy (the earliest node will be removed by default). Note: the scale-in is performed by the scaling group. TKE cannot detect the specific scale-in nodes and cannot drain or cordon in advance.
After you enable auto scaling, we recommend that you do not manually adjust the size of a node pool.
Do not directly adjust the desired capacity of a scaling group in the console.
Please scale in the node pool through auto scaling. During auto scaling, the node is first marked as unschedulable, all Pods on the node are drained or deleted, and then the node is released.
You can modify the node pool name, the operating system, the number of nodes in the scaling group, and the Kubernetes label and taint.
Modifications of the label and taint take effect for all the nodes in a node pool and may cause Pods to be rescheduled.
Adding an existing node
You can add Pods that do not belong to the cluster to the node pool. The following conditions are required:
The Pods and the cluster belong to the same VPC.
The Pods are not used by other clusters and have the same model and billing mode configurations as the node pool.
You can add nodes in the cluster that do not belong to any node pool. It requires the node Pods and the node pool must be configured with the same model and billing mode.
In normal cases, we recommend that you directly create a node pool instead of adding an existing node to a node pool.
Removing a node from a node pool
You can remove any node from the node pool and you can choose to whether to retain the node in the cluster.
Do not add nodes to the scaling group in the console, which may result in data inconsistency.
Converting an existing scaling group into a node pool
You can convert an existing scaling group into a node pool. After the conversion, the node pool inherits all the features of the original scaling group, and the information about the scaling group will not be displayed.
After all existing scaling groups in a cluster are converted into node pools, this feature will be disabled.
This operation is irreversible. Ensure that you are familiar with the features of node pools before conversion.
Related Operations
You can log in to the Tencent Kubernetes Engine console and perform node pool-related operations according to the following documents: